
Stories from Big Data Technology Warsaw 2019
Although the Big Data Technology Summit in Warsaw took place in February, there are plenty of takeaways that have definitely not grown old in this time. Like most attendees, I went there to get new ideas, to discover technologies that we could use at Softjourn and implement in our everyday work, ...
Although the Big Data Technology Summit in Warsaw took place in February, there are plenty of takeaways that have definitely not grown old in this time. Like most attendees, I went there to get new ideas, to discover technologies that we could use at Softjourn and implement in our everyday work, as well as to find some inspiration and expand my programming horizons. At this year's Summit, more than 60 Big Data experts from world-class companies like Amazon, Booking.com, Cloudera, and Confluence, shared their best practices.
Although the Big Data Technology Summit in Warsaw took place in February, there are plenty of takeaways that have definitely not grown old in this time.
Like most attendees, I went there to get new ideas, to discover technologies that we could use at Softjourn and implement in our everyday work, as well as to find some inspiration and expand my programming horizons. At this year's Summit, more than 60 Big Data experts from world-class companies like Amazon, Booking.com, Cloudera, and Confluence, shared their best practices.

The one-day conference was organized into 4 simultaneous sessions that focused on Architecture; Operations and Cloud; Data Engineering; Artificial Intelligence and Data Science, and Streaming and Real-Time Analytics. For my work, the most promising were Data Engineering, and Streaming and Real-Time Analytics.
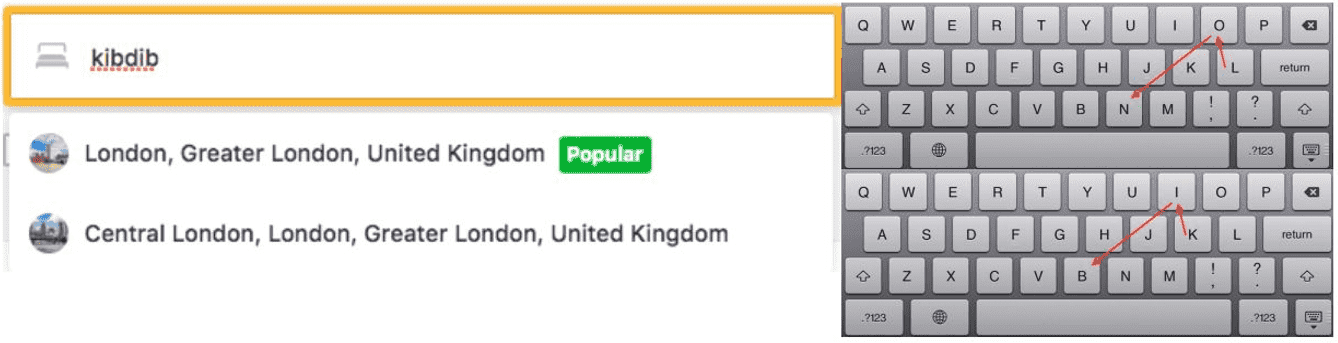
For starters, I was impressed by what experts from Booking.com told us about how to process nearly 1 billion user interactions every day to find the top 5 results for any given search query. They focused on user behavior and how this helped them build a powerful, personalized search, making the experience of booking a trip easier for travelers. The Booking.com speakers presented a very strange case involving advanced searching features used by Booking.com: when the speaker wrote "kibdib," the search engine correctly returned results for London. It did so on the correct assumption that the right hand of the typist had shifted one letter to the left. This feature was an excellent example of how to use an enormous database of user inputs to second-guess mistyped input in a business that involves looking up locations.
A more ground-breaking presentation at the Summit was the merger between Cloudera and Hortonworks. As two of the biggest players in the Hadoop big data space, both companies were known for reducing the complexity of Hadoop and implementing customized Hadoop ecosystems for organizations. Together, Cloudera and Hortonworks will be able to offer clients more complex services and products, such as end-to-end cloud big data solutions and support for more innovative organizations. At Softjourn, for instance, we might be able to use more Cloud Power to compute Machine Learning Modules.
The second trend I paid attention to was cloud transformation and the rising popularity and importance of Kubernetes. Kubernetes allows us to run containers across multiple compute nodes. Once Kubernetes takes control over a cluster of nodes, containers can then be spun up or torn down, depending upon the company's need at any given time. Kubernetes can also host different services, including big data tools like Apache Spark, Apache Kafka or Presto, data-science and AI tools like Jupyter, TensorFlow or PyTorch, and many other applications and microservices. From a data perspective, however, Softjourn might find it better to keep using managed cloud storage systems and databases, as they are cheaper and simpler to maintain than the Hadoop file system.
Of course, there was a lot of information about technologies that have been used for several years like Apache Spark, Apache Flink or Apache Nifi. Open Source solutions are likely to keep expanding significantly in the market, as their creators keep making considerable improvements to speed up data processing. For companies like Softjourn, it means shorter timeframes for delivering the desired results to clients.

The Warsaw Conference also held two parallel roundtables discussions that engaged all the participants. This gave us the opportunity to exchange opinions and experiences about a specific issue that was important to each group. Next, all participants were given the opportunity to meet and talk with the leaders of the roundtables, all of them professionals with vast knowledge and experience on their specific topics. I took part in both sessions: "Data Ingestion in 2019" and "Data visualization—How to visualize large, complex and dirty data and what tools to use." For me, it was particularly worthwhile to talk with people about the problems and challenges that they faced while experimenting with tools like Apache Nifi or Apache Superset, because these are tools that we use at Softjourn. That part was probably interesting to most of the participants as they were able to ask questions and get to know what tools others use during data acquisition and what issues came up during this process. I found it quite inspiring.
The 2019 Conference ended with a panel of 4 experts talking about the outlook for the next while and issues that were emerging: how current trends are changing the Big Data landscape, what it means to companies like ours, and how Hadoop and open-source ecosystem will look down the line. The hottest topic was, again, Kubernetes at the cost of the Hadoop ecosystem , and how the Cloudera-Hortonworks merger will develop as these two big players, who were competitors in the Hadoop environment, joined their forces. For now, it's a little bit early for Kubernetes, but they agreed that its times is coming and companies like ours should be ready for the next step.
Other topics the panelist considered were the increasing popularity of open source solutions in the cloud environment, the shortage of data scientists shortage, and the growing role of AI/ML. Clearly, the movement towards cloud computing can bring additional benefits to companies such as ours, and give them that competitive advantage in the business environment. The panelists also noted that data scientists are crucial to turning the massive volume of data companies generate into action. As Booking.com illustrated, this allows companies to get the insights from their data to personalize the user experience. Demand for this is high and growing, yet there aren't enough good professionals on the market.
On a more entertaining side, the Summit had play points, where participants could try out games on the pioneers of the industry, Nintendo, Commodore, Atari, and so on. I don't know about anyone else, but it took me right back to my childhood.
In short, the 2019 Big Data Tech Warsaw Summit was a great event that emphasized the continuing and growing importance of data and data management in a fast-changing world. I probably wanted a little bit more in the way of technical details, but I know that presentations can't reveal too many details. I still came away inspired.








