
Why Most CTOs Pick the Wrong Technology Stack (And How to Avoid Their Mistakes)
Did you know that 70% of enterprise technology projects fail due to poor stack selection? Despite the best intentions, many CTOs choose frameworks, languages, or tools that seem innovative but ultimately lead to significant technical debt. This article explores real-world case studies where stack...
Did you know that 70% of enterprise technology projects fail due to poor stack selection? Despite the best intentions, many CTOs choose frameworks, languages, or tools that seem innovative but ultimately lead to significant technical debt.
This article explores real-world case studies where stack decisions went off track and analyzes the core reasons why. Using these examples, we offer practical guidelines to help technology leaders make smarter decisions that align with business goals, team capabilities, and long-term scalability.
Did you know that 70% of enterprise technology projects fail due to poor stack selection? Despite the best intentions, many CTOs choose frameworks, languages, or tools that seem innovative but ultimately lead to significant technical debt.
The same mistakes tend to repeat: selecting trending technologies without evaluating business fit, underestimating long-term maintenance needs, or picking tools that do not match the team's existing expertise. These missteps often result in costly rewrites, performance issues, and frustrated development teams.
This article explores real-world case studies where stack decisions went off track and analyzes the core reasons why. Using these examples, we offer practical guidelines to help technology leaders make smarter decisions that align with business goals, team capabilities, and long-term scalability.

Common Triggers Behind Poor Tech Stack Decisions
Technology leaders often fall into predictable patterns that undermine their stack decisions. The excitement of selecting new technologies frequently overshadows critical thinking about long-term implications.
Technical debt accumulates silently until organizations find themselves trapped in costly, inefficient systems that hinder rather than help business growth.
Overvaluing Trendy Frameworks Without Business Fit
CTOs frequently select technologies based on industry buzz rather than strategic alignment. Research shows this approach creates a significant mismatch between business models and stack complexity1. The allure of cutting-edge frameworks often blinds decision-makers to more practical considerations.
Social proof becomes a dangerous substitute for evidence-based selection. As one study notes, "companies want to stay ahead of the curve and be considered innovative. Therefore, they decide to use trendy technology because everybody does".2 This herd mentality leads to implementing technologies that are difficult to implement, requiring workarounds and increasing maintenance costs.
Underestimating Long-Term Maintenance Costs
Many organizations fail to appreciate that initial development represents merely the beginning of their technology investment.
According to an analysis of enterprise software projects, maintenance accounts for approximately 75% of the total work in large codebases.3 This ongoing burden includes testing, diagnosing and fixing bugs, optimizing performance, upgrading it to work with other changes, refactoring, customer support, and writing documentation.
The subscription model for software creates another hidden cost trap. While initially affordable, expenses mount over time, especially as teams expand and require additional licenses. Plus, there are often concealed fees for premium features, support, or extra storage that weren't initially apparent.4

Ignoring Team Skill Alignment During Selection
One of the most overlooked aspects of technology stack selection is team alignment. Organizations often choose frameworks without considering whether their developers have the necessary experience to implement and maintain them effectively.
This misstep introduces immediate friction. Teams working with unfamiliar technologies face steep learning curves, leading to slower development, increased bugs, and inconsistent implementation. Leadership may focus on technical specs while underestimating the cost of onboarding, training, and decreased productivity.
When tools don't match a team's capabilities, adoption suffers - and ROI follows. Budget owners are then left questioning why an expensive platform isn't being used or creating value.
Take, for example, the decision to use Ruby on Rails. It's often selected for its speed, simplicity, and extensive libraries that support rapid development. However, these benefits only hold when the team is already proficient in Ruby: "The learning curve of the programming language should align with your developers' proficiency to avoid productivity bottlenecks".5 Forcing a team to upskill mid-project may cancel out any intended gains.
Selecting technologies aligned with team expertise can significantly reduce development time and improve code quality.6 This alignment creates a foundation for successful implementation rather than setting teams up for frustration and failure.

Where Things Go Wrong: Real-World Case Studies
To better understand why so many technology projects go off track, we analyzed a series of real-world case studies from companies across various industries.
Each company faced serious technical challenges tied directly to its technology stack choices. From overly complex architectures to poor performance and scalability issues, the root causes were surprisingly consistent.
In this section, we'll highlight three representative examples that show what happens when stack decisions don't align with product needs or team capabilities. Then, we'll break down the key patterns that emerged across all cases, and what CTOs can learn from them.
Case 1: Microservices Overhead in a Simple SaaS Product
A promising SaaS startup adopted microservices architecture prematurely, illustrating a classic case of technology overkill. The company acquired several disparate technologies over 18 months, creating a fragmented system where ownership constantly shifted between team members.7
Originally, this approach seemed forward-thinking - by breaking the application into smaller, independent services theoretically offered scalability benefits. However, as no team member had the expertise or focus to properly manage the platform, the system became increasingly chaotic. Automations, triggers, and new fields were added reactively without documentation of their functionality.
The fundamental mistake was implementing complex architecture before the product required it. As one analysis concludes, "microservices are a way of coping with complexity... this advantage does not come for free".8 Instead of enabling growth, the microservices approach became "a millstone around the neck" for a product that needed rapid iteration rather than distributed systems overhead.
Eventually, the company reached the platform's limits for adding new fields and using certain API triggers, causing core functionality to stop working. Frustrated team members abandoned the sophisticated solution entirely, resorting to spreadsheets instead of utilizing the overengineered stack.

Case 2: Choosing React Native for a High-Performance Game
A gaming company selected React Native for developing a high-performance mobile game, which was a decision that created insurmountable technical challenges for them.
While React Native offers cross-platform development benefits, it fundamentally lacked the performance capabilities necessary for what they needed for a graphics-intensive gaming experiences.
The development team quickly discovered that JavaScript thread performance suffered dramatically.9 Despite React Native's promise to deliver "at least 60 frames per second," the application consistently dropped frames during complex animations and interactions. This poor performance stemmed from React Native's architecture, where the JavaScript thread handles calculations that should ideally run on the main thread with native code.
Performance diagnostics revealed that any process taking longer than 100ms created noticeable lag for users. For games requiring advanced physics or rendering, these limitations proved disastrous. The team attempted to optimize by leveraging native modules, yet the fundamental mismatch between tool and requirement remained.
Although React Native supports cross-platform development with a single codebase, potentially reducing costs by eliminating separate development teams10 - this advantage became irrelevant when the resulting product failed to meet basic performance requirements.
Case 3: Ignoring Database Scaling in a Fintech App
A fintech company launched with a traditional monolithic SQL database that initially performed adequately. However, as transaction volumes increased, the system struggled with scalability and performance. Real-time analytics became virtually impossible due to latency and batch processing delays.11
The CTO's critical error was failing to anticipate scaling requirements for financial data processing. The database architecture lacked provisions for horizontal scaling—the ability to add more resources to distribute workload.12 Additionally, the team overlooked essential load balancing techniques, creating bottlenecks during peak transaction periods.
Performance deteriorated rapidly, with query response times stretching from milliseconds to minutes. For a financial application where transaction speed directly impacts user trust, this degradation proved catastrophic. Inefficient database queries significantly impacted overall application performance, leading to slow response times and increased server load.
After conducting a thorough technical assessment, the company migrated to a distributed database with an HTAP (Hybrid Transactional/Analytical Processing) architecture. This modification enabled them to handle thousands of transactions per second with minimal latency and perform real-time analytics simultaneously.11
The transformation resulted in improved decision-making capabilities and enhanced customer responsiveness, though at a significant migration cost that could have been avoided with proper initial planning.
Patterns in Stack Failure
Across the case studies, three distinct patterns emerged that consistently led to technology stack failures. Each pattern represents a critical disconnect in how organizations approach technology selection and implementation.
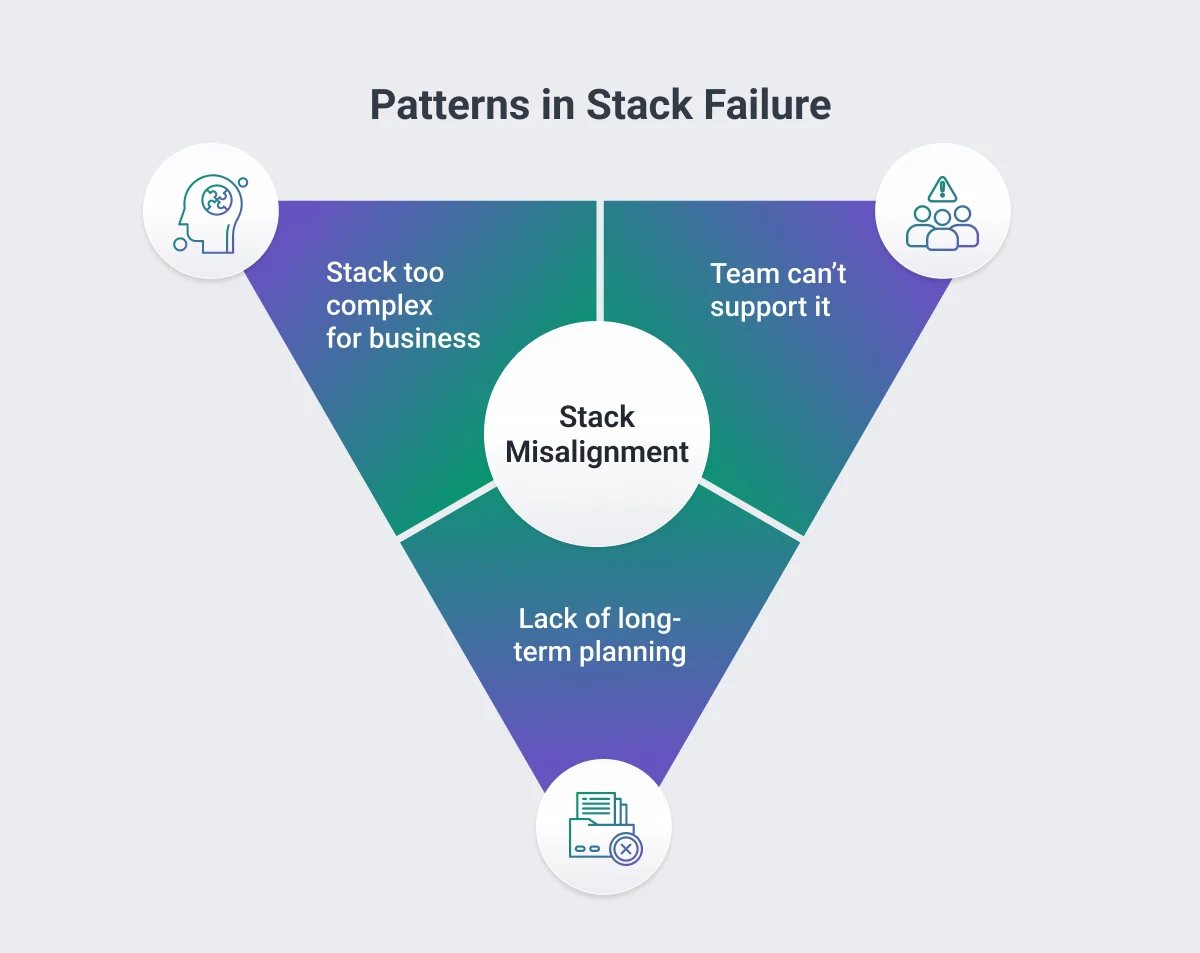
Mismatch Between Business Model and Stack Complexity
A fundamental error in tech stack selection occurs when organizations implement unnecessarily complex architectures that don't align with business requirements.
Many companies introduce multiple layers and components—each "best in class"—yet the combined system creates slowness, unreliability, and excessive costs.13 This approach leads to applications that become slow due to numerous layers, complex because of multiple handoffs, and unreliable as each layer introduces unique failure modes.
In customer-based businesses, poor tech stack choices directly impact customer experience through slow loading times and outages, resulting in higher churn rates.14 Additionally, fragmented tech stacks create data silos, making it impossible to get a unified view of business operations, which is essential for strategic decision-making.15
Delayed Refactoring Due to Early Stack Lock-in
Early commitment to inappropriate technology creates technical debt that becomes increasingly difficult to address. Indeed, 90% of companies' IT budgets are spent on software maintenance and support rather than innovation.16 Once organizations are deeply invested in a problematic stack, the sunk cost fallacy often prevents necessary changes.
For refactoring to be valuable, it must address real needs rather than speculation.17 Still, many organizations struggle with large-scale refactoring that can't fit within standard development cycles.18 Changing core architectural components often means deleting and recreating resources, a process that puts critical business data at risk.19
Impact of Poor Documentation on Developer Onboarding
Poor documentation creates substantial hidden costs by extending onboarding time for new developers. Many engineering teams lag in creating high-quality internal documentation, yet the cost of inconsistency is far greater than embedding documentation into daily processes.20
Without proper documentation, new team members spend excessive time searching for answers, reinventing solutions, or making preventable mistakes. This situation leads to significant delays in productivity, with some developers unable to contribute effectively for weeks or even months.
Ultimately, the quality of documentation can make or break a developer's onboarding experience, directly affecting a company's ability to evolve its technology.
How to Choose the Right Tech Stack for Long-Term Success
Avoiding stack selection pitfalls requires more than avoiding buzzwords. It demands a methodical evaluation of what you're building, who is building it, and how your system will scale and evolve. Here's how to approach this crucial decision with long-term viability in mind.

1. Start With the Product's Scope, Not the Stack
Before comparing tools, define the product's purpose and expected lifespan. Is it a fast-moving MVP with short-term goals? Or a platform expected to grow steadily over five years?
- For short-term products, rapid development frameworks (e.g., MEAN or Firebase) offer speed and flexibility.
- For long-term systems, prioritize modular, maintainable architectures (e.g., Spring Boot, Django, or Next.js) that won't require major rewrites down the road.
Also, anticipate evolution. If you foresee integrations, analytics, or expanded user roles, select a stack that can support those use cases without needing a full rebuild.
2. Align With Your Team's Existing Strengths
Technology decisions should empower, not hinder, your team.
- Choose tools that your engineers already know if you're under delivery pressure.
- If timelines allow, invest in a future-ready stack, but make sure you budget time for code audits, onboarding, and training.
- Consider third-party support for changing tech stacks or supplementing your in-house team.
A stack that looks ideal on paper becomes a liability when no one on your team can debug production issues or optimize performance.

3. Don't Ignore External Constraints
Stack choices aren't made in a vacuum. Real-world demands such as compliance, budget, and integration needs should inform every layer of your architecture.
- Compliance & Security: In fintech or healthcare, ensure your stack supports audit logging, role-based access control, and future-proof encryption methods.
- Budget: Account for licensing fees, infrastructure, managed services, and hidden costs like third-party API usage or vendor lock-in.
- Integration: Legacy systems and third-party dependencies can break if your stack doesn't play well with others. Plan for upstream and downstream data flows.
4. Evaluate the Stack's Long-Term Maintainability
What's sustainable today may become fragile tomorrow. Look for:
- Predictable upgrade paths: Frequent breaking changes or poor community support can introduce instability.
- Clear documentation and ecosystem maturity: This eases onboarding and reduces dependency on in-house knowledge.
- Operational simplicity: If your stack demands constant tuning or DevOps involvement, it may not scale with a small team.
Ask yourself: will this stack still work if half the original developers leave?
5. Weigh Performance, Scalability, and Operational Complexity
Choosing a stack means managing trade-offs:
- Performance under load: Some stacks favor concurrent, lightweight operations (e.g., Node.js), while others excel at CPU-heavy transactional work (e.g., Spring Boot).
- Scalability model: Can you scale horizontally via more instances, or are you stuck vertically scaling a monolith?
- Operational complexity: Can your team deploy and monitor reliably, or are you setting up a future filled with outages and duct-tape fixes?
A Stack Is a Strategic Bet—Make It Count
No stack is future-proof, but some are far more adaptable. The right choice aligns with your business vision, product goals, team skills, and the demands of scale. It enables rapid development now, without turning into a liability later.
The best CTOs don't just pick tools. They build systems that last.
Examples in Action
Softjourn helped a financial institution migrate from a legacy banking platform to a modular, multi-vendor system. By developing a robust integration layer and aligning 30+ vendor systems, we ensured a smooth transition without service disruptions—avoiding the long-term consequences of stack lock-in. Read the case study →

Make Stack Decisions That Enable Growth
Technology stack selection represents one of the most consequential decisions CTOs face throughout their careers.
Done right, it enables scalability, performance, and faster delivery. Done wrong, it leads to technical debt, stalled innovation, and frustrated teams.
Don't let early decisions become future roadblocks. Evaluate carefully, build strategically, and invest in a stack that grows with you.
Need help evaluating or optimizing your tech stack? Let's talk.








