
Guide to Hyper-Resiliency in Applications: What It Is and Why It Matters
Hyper-resiliency in applications ensures that your business can withstand and quickly recover from unexpected failures, disruptions, or even cyberattacks. Our guide explores what hyper-resiliency is, why it's critical for modern organizations, and how to build it into your systems.
Hyper-resiliency in applications ensures that your business can withstand and quickly recover from unexpected failures, disruptions, or even cyberattacks.
Our guide explores what hyper-resiliency is, why it's critical for modern organizations, and how to build it into your systems.
In today's fast-paced digital world, application downtime or poor performance can lead to significant losses in revenue, customer trust, and business reputation.
Hyper-resiliency in applications ensures that your business can withstand and quickly recover from unexpected failures, disruptions, or even cyberattacks.
This guide explores what hyper-resiliency is, why it's critical for modern organizations, and how to build it into your systems.

What is Hyper-Resiliency in Applications?
At its core, hyper-resiliency refers to the ability of an application to continuously adapt and recover from disruptions with minimal to no impact on users.
While traditional application resiliency focuses on recovering from failures, hyper-resiliency goes a step further by integrating advanced features like proactive problem detection, automated recovery, and seamless scaling.
Key Characteristics of Hyper-Resilient Applications:
- Fault Tolerance: Ability to continue operating even when components fail.
- Disaster Recovery: Swift restoration of services in the event of a major incident.
- Proactive Cybersecurity: Defense mechanisms that adapt in real time to emerging threats.
- Automated Scaling: Capability to handle increased traffic or workloads without human intervention.
To build these capabilities, companies often turn to DevOps consulting services to implement robust automation and monitoring solutions.

Why Hyper-Resiliency is Crucial
Application downtime doesn't just inconvenience users; it can severely damage a business. Whether you are managing an e-commerce platform, financial services, or a digital product, hyper-resiliency is key to ensuring seamless operations.
Key Benefits of Hyper-Resiliency:
- Minimizing Downtime: Hyper-resilient applications reduce or eliminate downtime, allowing businesses to maintain continuous operations.
- Protecting Revenue: With applications that recover quickly from failures, businesses can avoid revenue losses due to service interruptions.
- Safeguarding Reputation: Frequent outages or security breaches can damage a company's reputation. Hyper-resilient applications help prevent such incidents, ensuring a more reliable user experience.
- Mitigating Risk: Proactive threat detection and automated scaling capabilities reduce the risk of losing customers or data due to unexpected incidents.
Companies looking to enhance their fault tolerance and scalability often leverage CI/CD consulting services to streamline deployments and reduce failures in production.

How to Build Hyper-Resilient Applications
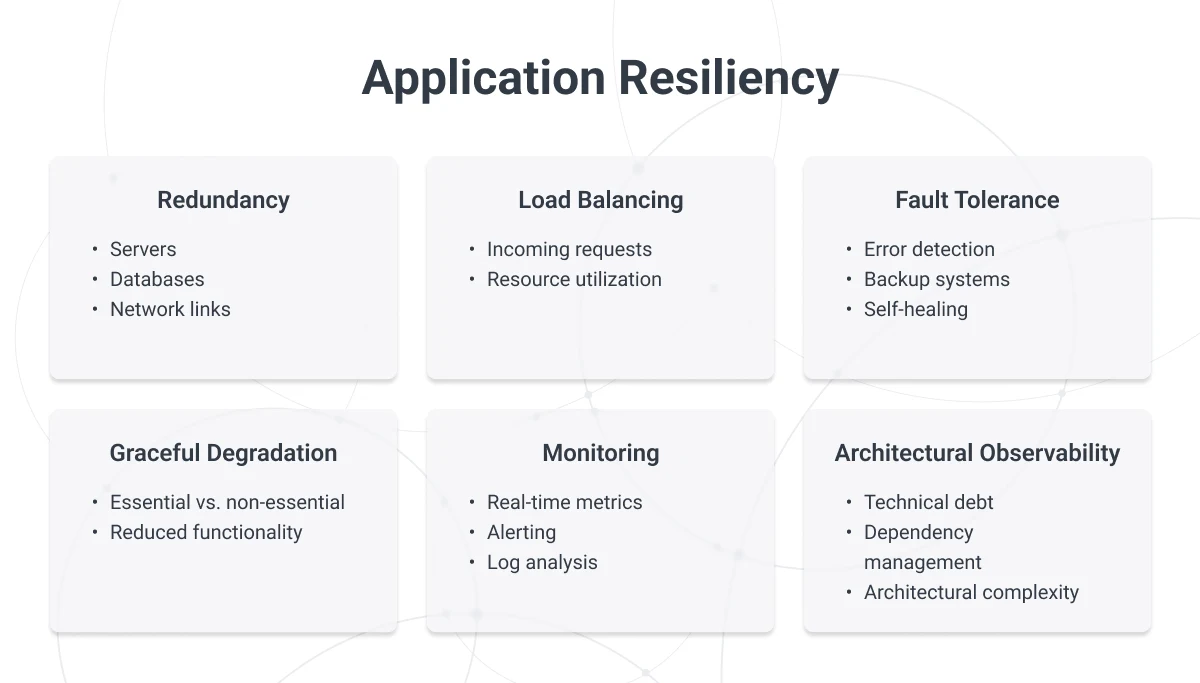
Building hyper-resilient applications requires a multi-faceted approach that involves redundancy, monitoring, fault tolerance, and constant optimization.
Redundancy
Redundancy eliminates single points of failure by duplicating critical system components.
- Data Centers and Servers: Distribute applications across multiple servers and data centers. This ensures that if one fails, another can take over without disruption.
- Database Replication: Replicate your data across multiple databases to prevent loss and maintain availability in the event of a failure.
- Network Redundancy: Establish alternative network paths to ensure connectivity even if a primary network link fails.
Companies often outsource DevOps services to implement redundancy strategies efficiently.
Load Balancing
Load balancing helps distribute traffic and workloads evenly across servers, reducing the risk of bottlenecks and ensuring high availability.
- Traffic Management: Load balancers distribute incoming requests to ensure that no single server is overwhelmed, enhancing both performance and reliability.
- Optimized Resource Use: By balancing workloads, resources are used more efficiently, preventing slowdowns or crashes during peak traffic periods.
For efficient container orchestration, businesses use tools like Kubernetes and Docker for scalable microservices architectures.
Fault Tolerance and Automated Recovery
Fault tolerance ensures the system can recover quickly from failures, minimizing user impact.
- Automatic Failover: Systems with fault tolerance can automatically switch to backup servers or components when a failure occurs, ensuring continuous availability.
- Self-Healing Systems: Some systems can automatically repair issues by restarting failed components or rerouting traffic, reducing the need for manual intervention.
Advanced Terraform automation can provision and manage infrastructure dynamically for fault-tolerant systems.
Graceful Degradation
When parts of an application fail, a hyper-resilient system prioritizes essential functions.
- Core Functionality First: Even in the event of disruptions, core business operations—such as transaction processing or account access—remain functional.
- User Communication: If secondary features are unavailable, clear communication helps manage user expectations and reduces frustration.
Continuous Monitoring and Observability
Hyper-resiliency is built on the ability to anticipate and quickly resolve potential issues before they affect users.
- Real-Time Monitoring: Monitor key performance metrics like server load, network traffic, and database health in real time to catch potential failures early.
- Automated Alerts: Set up automated alerts that notify your team as soon as a problem arises, allowing for faster response times.
- Predictive Analytics: Analyzing historical data can reveal patterns that predict future issues, enabling preventative maintenance and optimizations.
For an in-depth audit of your system's architecture, consider an architecture assessment or a technology audit to identify vulnerabilities early.
Examples of Hyper-Resiliency in Action
To truly understand the importance and impact of hyper-resiliency, let's dive deeper into real-world examples, highlighting companies that have successfully implemented hyper-resilient strategies and those that have faced challenges due to a lack of resiliency.
Success Stories of Hyper-Resiliency:

Netflix: Mastering Hyper-Resiliency with Chaos Engineering
Netflix is a prime example of how hyper-resiliency can be achieved at scale. With millions of users worldwide streaming content simultaneously, Netflix must ensure that its service remains available even in the event of unexpected system failures.
- Microservices Architecture: Netflix relies on a distributed microservices architecture where different services are loosely coupled. This means if one service fails, it doesn't bring down the entire platform.
- Chaos Engineering: Netflix popularized chaos engineering, a practice where controlled failures are introduced into their system to test how resilient the application is. For example, they deliberately turn off random servers or simulate network outages to ensure their systems can withstand real-world disruptions. This proactive testing allows them to identify weaknesses and improve resiliency before a failure affects users.
- Global Infrastructure: With a presence in multiple data centers worldwide, Netflix ensures redundancy. If one region faces issues, the load can be shifted to another region without service disruption. This seamless failover mechanism is critical to maintaining high availability.

Amazon: Hyper-Resiliency at Scale During Prime Day
Amazon is another leader in hyper-resiliency, particularly during high-traffic events like Prime Day. Handling billions of transactions globally requires a robust system that can scale and recover from failures without losing sales.
- Automated Load Balancing: Amazon uses sophisticated load-balancing techniques to ensure that traffic surges are evenly distributed across their data centers. During peak times, such as Prime Day, they automatically scale their infrastructure, adding servers and resources dynamically to handle the load without service degradation.
- Failover Mechanisms: Amazon has implemented advanced failover mechanisms where services can switch to backup systems in the event of failures. For example, if one warehouse management system goes down, orders are rerouted to other warehouses seamlessly, ensuring that customers receive their orders on time.
- Disaster Recovery Plans: In the case of significant regional outages, Amazon's global network allows them to reroute traffic and services to other regions without impacting the customer experience. This level of redundancy ensures that even in worst-case scenarios, Amazon remains operational.
Cautionary Tales: Failures Due to Lack of Resiliency:
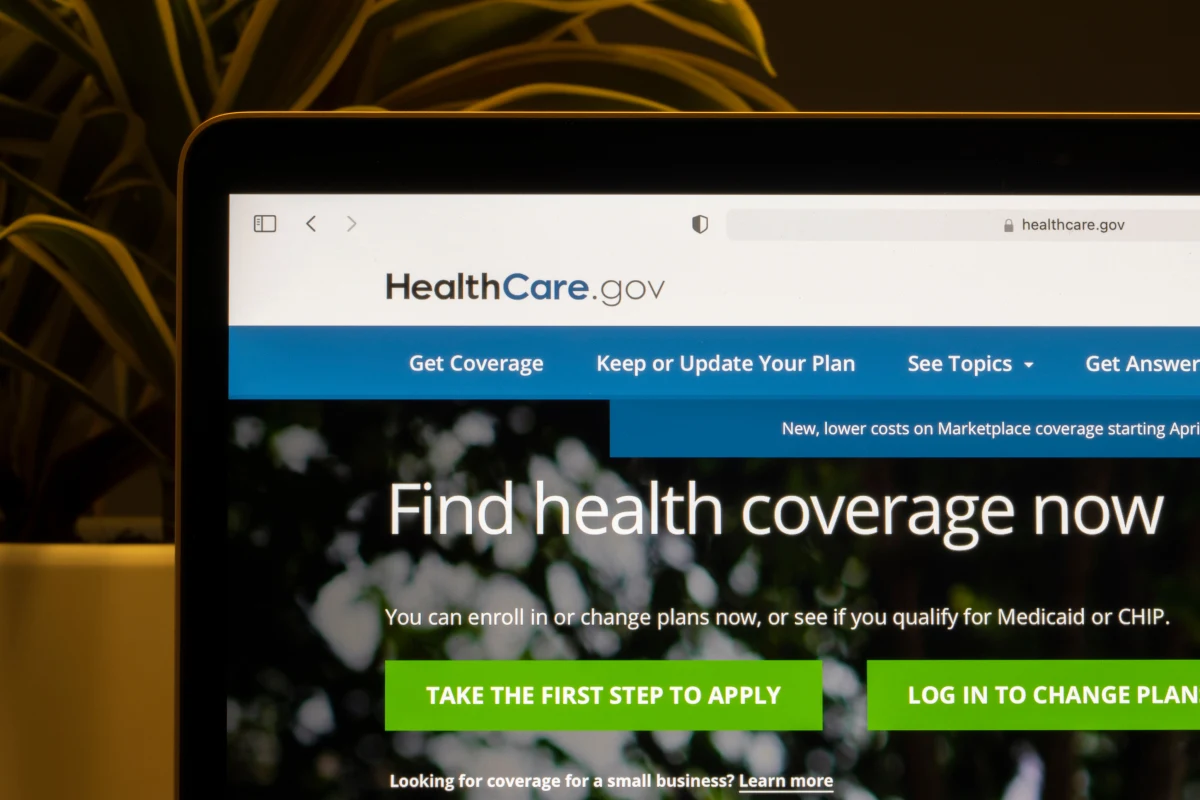
Healthcare.gov: A High-Profile Launch Failure
When the U.S. government launched Healthcare.gov, the website faced massive outages and performance issues, leaving millions of Americans unable to sign up for health insurance. This failure was due to inadequate planning and lack of scalability during the initial rollout.
- Inadequate Load Testing: The website was not adequately tested for the high volumes of traffic it received at launch. Without proper load balancing or redundancy, the servers were overwhelmed, leading to crashes and slow response times.
- Lack of Redundancy: With no proper failover mechanisms, the failure of key components meant that the entire system was affected, preventing users from completing their tasks. The site's single-point failures highlighted the importance of implementing a more resilient architecture.
Online Banking Outages: The Cost of Downtime
Many online banks have experienced significant outages due to insufficient planning for hyper-resiliency. For example, when a major European bank suffered a 48-hour outage due to a technical failure, customers were unable to access their funds, leading to widespread frustration and loss of trust.
- Failure to Implement Redundancy: The bank relied too heavily on a single data center for critical operations. When that data center experienced issues, there were no backups in place to handle the load, leading to a prolonged outage.
- Impact on Reputation and Revenue: This failure led to significant reputational damage, with customers switching to more reliable competitors. Additionally, the bank faced regulatory scrutiny and financial penalties due to the service disruption.
Best Practices for Achieving Hyper-Resiliency
To maintain and improve the resilience of your applications, follow these best practices:
- Design for Failure: Always assume that components will fail and build systems that can withstand and recover from these failures.
- Proactive Threat Mitigation: Incorporate advanced monitoring and security measures as well as implement cybersecurity audits to detect security threats early.
- Shift-Left Approach: Incorporate resiliency testing early in the development lifecycle to catch potential issues before they become problems.
- Use Microservices and Containerization: Microservices help to isolate failures and ensure that a problem in one service doesn't bring down the entire application. Ruby on Rails and Golang are commonly used for microservice development.
- Regular Testing and Simulation: Use chaos engineering to simulate failure scenarios, testing your system's ability to recover under real-world conditions.

Final Word
In a world where downtime is unacceptable, building hyper-resilient applications is more than just a technical requirement—it's a business necessity.
Organizations that invest in hyper-resiliency can provide uninterrupted services, ensure customer satisfaction, and protect their reputation, all while minimizing the risks of costly outages or security breaches.
At Softjourn, we specialize in auditing infrastructure and applications to ensure they are resilient and built to withstand future challenges. Our technical consulting services can help you identify vulnerabilities and implement the best practices needed to make your applications as resilient as possible.
Contact us today to safeguard your business and ensure you're ready for whatever the future brings!

Frequently Asked Questions
What is the difference between resiliency and high availability?
Resiliency refers to an application's ability to recover quickly from failures and maintain operations with minimal impact. High availability, on the other hand, ensures that the application is always accessible with minimal downtime. While they are related, resiliency focuses on recovery while high availability focuses on uptime.
How does chaos engineering contribute to hyper-resiliency?
Chaos engineering is the practice of intentionally introducing failures into a system to test how well it can recover. Companies like Netflix use chaos engineering to identify weaknesses before they cause real-world outages. This proactive approach strengthens resiliency by ensuring systems can withstand unexpected failures.
Can hyper-resiliency be achieved in legacy applications?
Yes, but it requires modernization efforts. Many legacy applications were not designed with cloud-native resilience in mind. Strategies like containerization, microservices migration, and automated failover systems can help modernize older applications and improve resiliency.
What role does AI and machine learning play in hyper-resiliency?
AI and machine learning can significantly enhance proactive monitoring, predictive maintenance, and anomaly detection. By analyzing past system failures, AI-driven tools can predict potential issues before they occur, allowing teams to fix them before they impact users.
Is hyper-resiliency only important for large enterprises?
No. While large enterprises invest heavily in resiliency, small and mid-sized businesses also benefit. A single unexpected outage can be devastating for a startup or growing business. Implementing even basic resilience strategies—like automated backups, failover mechanisms, and monitoring—can prevent costly downtime.
How can startups ensure their applications are resilient from the beginning?
Startups should consider an independent startup audit early to identify infrastructure weaknesses. Additionally, startup consulting services can provide guidance on building a strong and scalable foundation.
What are the biggest challenges in building a hyper-resilient application?
Some common challenges include:
- Cost and complexity – Implementing redundancy, failover systems, and real-time monitoring can require a significant investment.
- Balancing performance and resilience – Some resilience mechanisms, like frequent data replication, can introduce latency.
- Security risks – While resilience helps maintain uptime, poor security practices can make a system vulnerable to cyberattacks.
How does cloud computing improve application resiliency?
Cloud platforms provide built-in scalability, redundancy, and automated failover capabilities. Services like AWS, Azure, and Google Cloud offer multi-region deployments, ensuring applications remain operational even if one data center fails.
Can hyper-resiliency prevent cyberattacks?
Hyper-resiliency does not prevent cyberattacks, but it helps applications recover quickly from security breaches or outages caused by attacks. Strong security measures—such as automated threat detection, real-time monitoring, and zero-trust security models—should be combined with resiliency strategies.
What are some real-world consequences of poor application resiliency?
Companies that fail to invest in resiliency often experience:
- Revenue loss – Downtime can result in lost sales, especially for e-commerce and financial services.
- Reputation damage – Customers lose trust in unreliable services.
- Regulatory penalties – Industries like healthcare and finance face legal consequences for service interruptions.
- Customer churn – Users may switch to competitors with more reliable services.
How often should an application's resiliency strategy be tested?
Regular testing is crucial. Best practices include:
- Quarterly disaster recovery drills to simulate system failures.
- Ongoing performance monitoring with automated alerting.
- Annual architecture assessments to evaluate whether existing resiliency measures are still effective as the system scales.
What are the key performance indicators (KPIs) for measuring application resiliency?
Some important resiliency KPIs include:
- Mean Time to Recovery (MTTR) – Measures how quickly the system recovers from failures.
- Mean Time Between Failures (MTBF) – Tracks how often failures occur.
- Service Level Agreements (SLAs) and Service Level Objectives (SLOs) – Ensure availability meets business expectations.
- Error Rate – Measures the percentage of failed requests compared to total requests.
Does building hyper-resiliency require a multi-cloud approach?
Not necessarily, but multi-cloud strategies can enhance resiliency by reducing reliance on a single provider. Deploying applications across multiple cloud providers prevents vendor lock-in and ensures failover capabilities if one cloud provider experiences downtime.
How can DevOps improve application resilience?
DevOps practices integrate automation, monitoring, and infrastructure as code (IaC), making applications more scalable, fault-tolerant, and secure. Our DevOps implementation services help businesses set up reliable CI/CD pipelines and cloud automation.
What tools help manage scalable infrastructure?
Popular tools for infrastructure automation and monitoring include:
- Terraform – for infrastructure as code.
- Ansible – for automated configuration management.
- Kubernetes – for container orchestration.
What are some programming languages for resilient applications?
Some of the most resilient and scalable programming languages include:
- Golang – Ideal for cloud-native applications, microservices, and distributed systems due to its efficiency and concurrency handling.
- TypeScript – Secure and scalable choice for front-end and back-end development, offering static typing for better maintainability.
- C++ – Used for high-performance systems, embedded software, and applications requiring low-level memory control.
- C# – Popular for enterprise applications, gaming, and cloud-based services using .NET technologies.
- Python – Widely used for AI, machine learning, automation, and backend web services. Its extensive libraries and simple syntax enhance resiliency.
- Java – One of the most widely used languages for large-scale enterprise applications, banking systems, and Android development.
- Ruby on Rails – A flexible and developer-friendly framework for building robust web applications.
What is a software architecture assessment, and why is it important?
An architecture assessment helps businesses evaluate their application structure to identify inefficiencies, bottlenecks, or potential failure points. This ensures systems remain scalable, secure, and resilient.
What role does business intelligence play in hyper-resiliency?
Business intelligence solutions provide real-time analytics and monitoring that help businesses predict failures, optimize performance, and enhance decision-making for application resiliency.








