
No Guessing Allowed: What We Learned Building an AI Chatbot
In February 2026, our R&D team developed an AI chatbot for the Softjourn website. The goal was a proof-of-concept chatbot grounded strictly in Softjourn's own documentation. The constraint we cared most about wasn't speed or cost, but trust. We wanted to ensure that if a prospect asked whether we...
In February 2026, our R&D team developed an AI chatbot for the Softjourn website. The goal was a proof-of-concept chatbot grounded strictly in Softjourn's own documentation.
The constraint we cared most about wasn't speed or cost, but trust. We wanted to ensure that if a prospect asked whether we'd worked in a specific domain or on a certain project type, the chatbot would be able to confidently answer, without hallucinating or making something up.
Every week, someone lands on our website with a specific question: "Have you built payment flows before?" "Do you have experience with Angular migration?" "Are you able to help me develop a ticketing app?"
The answer to these questions is yes, and the evidence is sitting right there in our case studies library. But finding it requires a website visitor some work: running a search, clicking through results, and reading. Not a bad experience, but not an immediate one either. And that first moment of "can these people actually help me?" is exactly when friction costs you.
In February 2026, our R&D team spent a week trying to close that gap. The goal was a proof-of-concept chatbot grounded strictly in Softjourn's own documentation. The constraint we cared most about wasn't speed or cost. It was trust. If a prospect asked whether we'd worked in a specific domain and the chatbot confidently made something up, we hadn't built a sales tool; we'd built a liability.
That's where the interesting problems started.
The Hardest Requirement Was Also the Most Important One
"Don't make things up" sounds like a low bar. In practice, it's one of the harder problems to actually enforce in an AI system.
Large language models are built to generate plausible responses. That's their default behavior. Left unconstrained, a chatbot will fill gaps in its knowledge with confident-sounding answers it has no business giving. For a general-purpose assistant, that's a known tradeoff. For a sales tool representing a company's actual capabilities, it's a serious problem.
Our requirement was explicit from the start: the chatbot could only answer from Softjourn's uploaded documentation. If the answer wasn't there, it had to say so. No inferring, no generalizing from outside knowledge, no helpful-sounding approximations.
Enforcing that required work at a few different levels.
The first was data preparation. We ingested our content in both structured formats (organized data with defined fields, like JSON and CSV files) and unstructured formats (open-ended text like Markdown documents and plain text). Each behaves differently inside the system. Structured data gives you more control and predictability; unstructured data handles conversational queries more naturally. Getting the chatbot to draw correctly from both took deliberate setup, not just an upload.

The second was prompt engineering. The system instruction given to the agent was direct: answer only from the provided context, use no external knowledge, and do not improvise. Prompt engineering, in plain terms, is the practice of writing precise instructions that shape how an AI model behaves. Small changes in how those instructions are written can produce meaningfully different outputs. Getting the wording right took iteration.
The third layer was structural. We disabled all public web connectors in the Vertex AI environment, which removed the possibility of the chatbot pulling in outside information entirely. And for the two question types most likely to generate problematic responses, competitor comparisons and pricing, we replaced open-ended answers with scripted fallbacks.
Ask about a competitor and the chatbot responds: "We focus on our own methodology and results; we do not comment on other providers." Ask about pricing, and it says that pricing is tailored to specific needs and routes to the sales team. Those answers are controlled, consistent, and appropriate.
The result is a chatbot that occasionally says "I don't have information on that" and means it. That might sound like a limitation, but we find it's the feature that makes it more trustworthy.
The Three-Question Limit Was a Design Choice, Not a Technical Constraint
Early in the project, we made a decision that had nothing to do with what the technology could handle and everything to do with what we actually wanted the chatbot to do.
After three exchanges, it stops answering questions and prompts the visitor to contact our sales team.
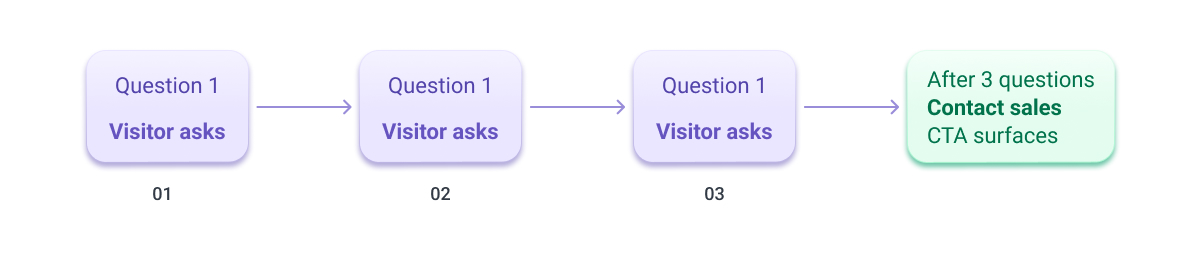
That probably sounds restrictive. It isn't. A chatbot that will answer unlimited questions indefinitely isn't a lead generation tool, it's a support portal. Those are different products with different goals. What we were building was designed to do one specific thing well: take a visitor who has a real question about Softjourn's capabilities, give them a fast, accurate answer, and then create a clear path to a human conversation.
We've found that three questions is enough to do that. It's enough for a prospect to confirm we've worked in their industry, understand the shape of our experience, and decide whether it's worth a conversation with our sales team. Beyond that, the value of the chatbot interaction starts to plateau, and the value of a real conversation increases. That said, we may find that more flexibility on the number of questions is needed, and we'll revisit this once we have real session data to learn from.
There's also something to be said for measurability. A consistent three-question flow creates a repeatable, trackable path from first visit to sales contact. Every session follows the same structure, which means you can actually measure what's working. An open-ended chatbot session is harder to analyze and harder to improve.
The implementation is straightforward: after the third exchange, the chatbot surfaces a "Contact Us" call to action and routes the visitor toward the sales team. What looks like a simple UI moment is actually the point the whole system is designed to reach.

What We Learned About Building on Vertex AI
Going into the project, we had a general familiarity with Google Cloud's Vertex AI platform. Coming out of it, we had something more useful: hands-on experience with where it excels, where it requires careful setup, and which tools inside the ecosystem are actually suited to which problems.
The first thing we tested was which agent type to build on. Three options were evaluated side by side.
A Conversational Agent worked well for guided chat interactions and was straightforward to configure. It hit a hard wall when we needed to return direct links to specific pages on the Softjourn website. It doesn't support structured datasets with defined schemas, which ruled it out for our use case entirely.
A Search UI was genuinely strong for document retrieval. It understood related topics, handled multiple languages well, and worked well against our actual case study content. But its interface customization was limited, and it was better suited to search-style discovery than a conversational experience. Close, but not right.
Customer Experience Agent Studio was the clear choice. It was the only option that handled structured data correctly and returned direct links to specific pages rather than links to raw documents. It also supported sub-agents, meaning different types of questions can be routed to specialized components within the same system, and it allowed callbacks to external platforms via APIs and MCP servers. MCP servers, or Model Context Protocol servers, are essentially a standardized way for AI tools to communicate with outside software like CRM systems or project management platforms. That extensibility matters for anything beyond a basic proof of concept.

The team's own read after building with it: "It is easy to use, set up, and can be used in different cases." That matches our experience. The platform has real depth, but the core setup is approachable enough that a focused team can go from zero to working proof of concept in a week.
A few things worth knowing if you're building something similar:
- Structured and unstructured datasets behave differently inside the platform and need to be treated differently from the start, not retrofitted later.
- Prompt engineering is not a finishing step. It's load-bearing work that shapes whether the grounding constraints actually hold.
- Test in a staging environment that closely mirrors your production setup. We hit a crash on our internal testing site that didn't appear in the basic setup, caught it, and fixed it before it became a real problem.

What We'd Tell Anyone Building Something Similar
The week we spent on this project was useful in ways that go beyond the proof of concept itself. A few things we came away believing more firmly than when we started:
- Grounding an AI chatbot in a specific document set is achievable, but it requires more deliberate setup than most people expect. The technology won't do it automatically. It needs structured data prepared correctly, prompt instructions written carefully, and external knowledge sources actively closed off. Each of those is a real step, not a checkbox.
- The design decisions matter as much as the technical ones. The three-question limit, the scripted fallbacks for competitor and pricing questions, the choice to surface a contact CTA at a specific moment: none of those were technical requirements. They were product decisions about what the chatbot was actually for. Getting those right made the technical implementation more focused and the final tool more useful.
- The barrier to entry is lower than it probably looks. A focused team with clear requirements can go from concept to working proof of concept in a week on this platform. The harder work is the thinking you do before you start building: what the chatbot is allowed to say, what it should never say, and what a successful interaction actually looks like. That clarity is what turns a demo into a tool someone would actually trust.
Ready to see what a grounded AI chatbot could do for your platform? We're happy to walk through what we built and what the same approach might look like for your use case. Get in touch with the Softjourn team to start the conversation.








