
AI False Positives: How Machine Learning Can Improve Fraud Detection
What's just as bad as false negatives? AI false positives. In 2018, false positives cost U.S. ecommerce merchants $2 billion in sales. Proactive fraud prevention is key, and financial institutions (FIs) are investing in a variety of new technologies to this end. One technology rising to the foref...
What's just as bad as false negatives? AI false positives. In 2018, false positives cost U.S. ecommerce merchants $2 billion in sales. Proactive fraud prevention is key, and financial institutions (FIs) are investing in a variety of new technologies to this end. One technology rising to the forefront is machine learning (ML).
What's just as bad as false negatives? AI false positives. In 2018, false positives cost U.S. ecommerce merchants $2 billion in sales.1 Proactive fraud prevention is key, and financial institutions (FIs) are investing in a variety of new technologies to this end. One technology rising to the forefront is machine learning (ML).
ML can help FIs meet the rising tide of transactions, which is growing even larger due to the pandemic's push on ecommerce and digital purchases.
ML is already being implemented in the financial industry with great success — but it isn't widely adopted due to misinformation and lack of knowledge. Let's take a closer look at ML and the problem it seeks to solve.
This type of technology is already being implemented in the financial industry with great success —but it has not yet been widely adopted due to misinformation and lack of knowledge. Let's take a closer look at the problem machine learning seeks to solve, and how it can accomplish that task.
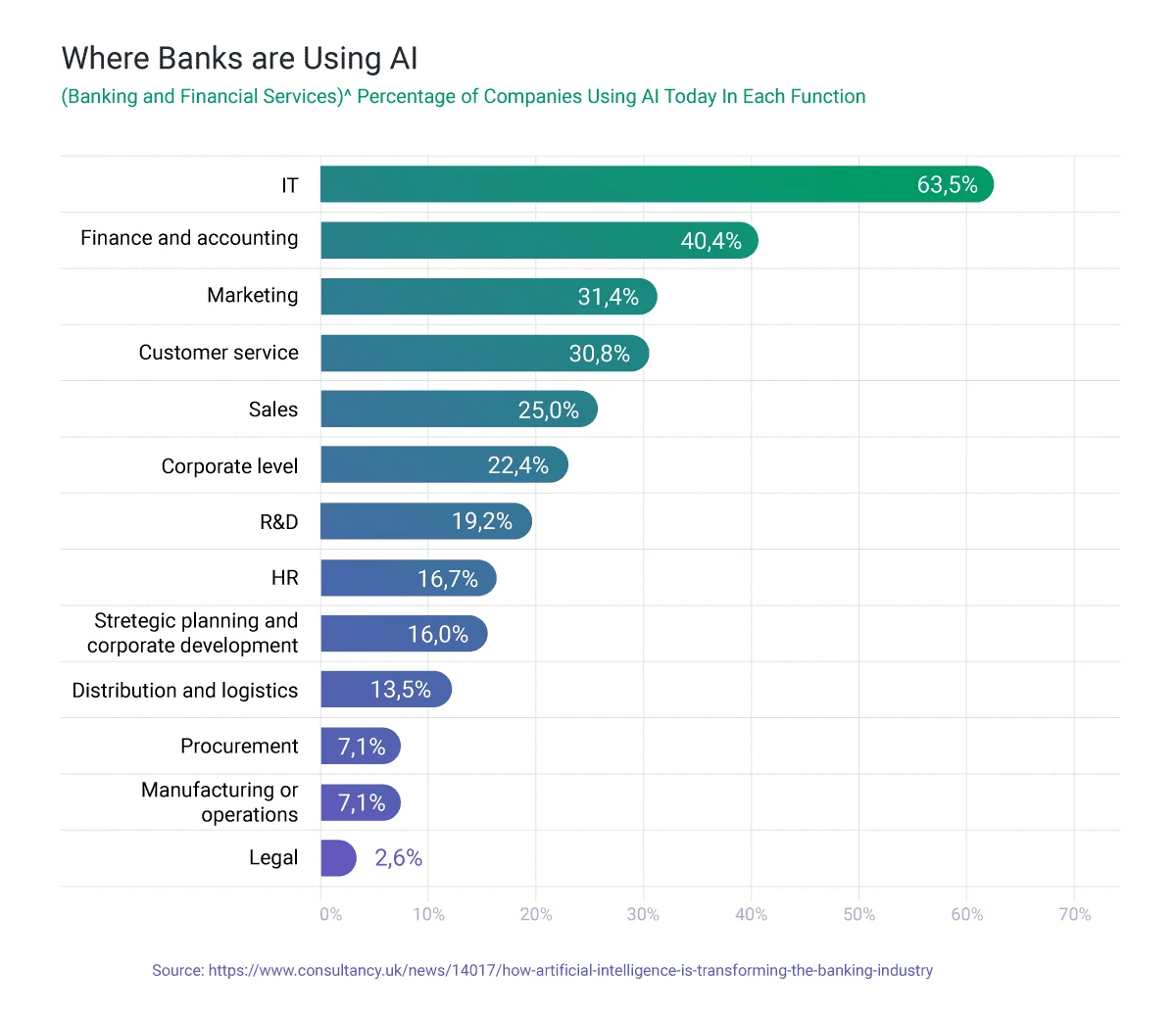
FIs are using machine learning in IT, finance and accounting, and marketing.
What is Machine Learning?
ML is the practice of "teaching" machines to recognize patterns in large amounts of data by defining input and output labels. While the term is often used interchangeably with artificial intelligence (AI), ML is actually a subset of this type of data science.
ML has already been used in many applications and technologies familiar today. Examples include website chatbots to provide better customer service, and receipt recognition to shorten the amount of time needed to input information and increase accuracy by removing human error.
FinCEN and other federal regulators recommend that FIs use AI and ML to meet AML compliance. The United Nations Office on Drugs and Crime estimates that money laundering affects between 2-5% of global GDP annually, which is equivalent to between $800 billion to $2 trillion.
ML and AI are useful tools that can automate both front and back office processes. They can help FIs mitigate issues before they happen. However, AI is not a silver bullet, and should be paired with human workers who can provide another layer of analysis for higher level issues.
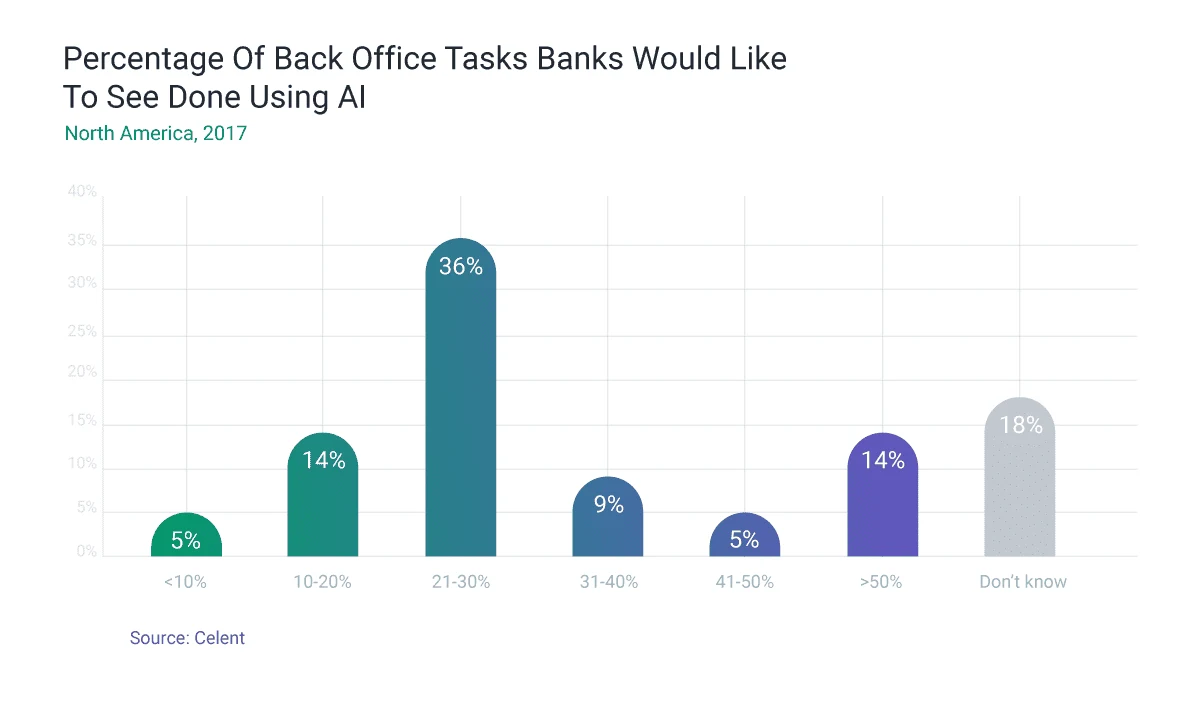
According to recent research 36% of FIs would like to see back office tasks automated using artificial intelligence and machine learning.
How Do False Negatives and AI False Positives Affect FIs?
For a financial institution, an AI false positive is when a user is incorrectly identified as a fraudster. This is typically the result of a legitimate transaction being flagged as suspicious, which in turn shuts down a valid payment or even results in completely locking down an account.
With ecommerce thriving amid the pandemic, false positives can have a serious impact on merchants, their customers, and the payments system as a whole. Digital fraud prevention company Kount reports that in 2018, false positives cost U.S. ecommerce merchants $2 billion in sales.
On the other end of the spectrum, an example of a false negative is when fraud gets past security measures. FIs that suffer too many false negatives can draw government scrutiny and penalization.
FIs tread a fine line between being too overzealous and not rigorous enough. The former can lead to damaging customer relationships, while the latter can enable criminal activity and risk drawing regulatory audits.
Why Rule-Based Fraud Detection isn't Enough
Technology is improving the quality of our lives and speeding progress at a blistering pace. FIs can process millions of transactions faster and with greater accuracy than ever before. According to estimates, global payments are expected to approach $3 trillion in the next five years.2
But this also creates a bigger opportunity for fraudulent transactions. By sneaking in through the thousands of valid transactions processed every fraction of a second, fraudulent activity grows harder and harder for humans to detect. McAfee estimates that cybercrime cost the global economy about $600 billion in 2018.3 The number of institutions experiencing financial fraud, whether successful or not, also continues to increase year over year.
Humans can't keep up with the rapid development of technology. This means they end up relying on the same technology to combat the issues that arise from the new and changing processes that technology creates. However, many FIs still rely on rule-based fraud detection, which are manual systems created by fraud analysts that cannot keep up with the real-time data streams that are increasing at a frequent pace.
Rules-based mechanisms are also not flexible enough for the changing nature of consumer behavior on a global scale. As consumers have increasing access to their financial and payment information via a widening number of channels, this creates a larger number of ways to complete transactions.
Since it's difficult for rules-based systems to understand when a deviation from the norm is acceptable, this often generates AI false positives that indicate lost transactions and lost revenue for the business. A financial institution using rules-based mechanisms can take 40+ days to detect fraud.4

While technology improves our lives, it also provides more opportunities for fraud.
This leaves customers wondering and waiting if their accounts have been tampered with, and if their information or their money has been stolen. According to Altexsoft, 20% of customers change banks after experiencing a scam. FIs risk their business and reputation when they waste hours and money on unnecessary customer interactions trying to understand if a transaction was valid or not. Multiply this scenario by the thousands of transactions now happening every second and it's easy to see how this quickly becomes problematic at many levels.
But with ML, FIs can combat fraud by using the information they already have. Let's take a closer look at how it can help prevent financial fraud.
How to Reduce False Positives in Machine Learning
ML builds a baseline mathematical model from "training data" using the direction of an algorithm. This allows a machine to make predictions without being explicitly programmed to perform a specific task. The more data a machine has to "learn" from, the more accurate it will be. This technology can be used to identify normal consumer spending and differentiate it from activities that might be associated with a fraudulent charge.
Payments are one of the most digitized parts of the financial industry, due to the rise of mobile payments and the increasing need for a better customer experience. Because they are so digitized, payments are vulnerable to digital fraudulent activity.
Banks that are trying to retain clients and lure prospects away from competitors want to provide the best experience for their customers. They do this by whittling down the number of verification steps involved in completing a transaction, which lessens the effectiveness of rule-based systems.
ML can fill in the gap because it can not only review existing data to learn about customer spending habits, but eventually understand the fluctuating nature of customer spending throughout the year (for example, travel at different times of the year, holiday spending, etc.).
Because of this, ML can lessen the number of AI false positives typically identified by rules-based systems that cannot distinguish anomalous but not necessarily fraudulent behavior. One case study from Teradata showed that the implementation of ML reduced false positives by 60%, and was expected to rise to 80% as the model continued to learn.5

Machine learning can help humans search through terabytes and petabytes of data, and reduce the number of AI false positives.
Supervised vs. Unsupervised Models: Which Should You Use?
One of the easiest types of fraud to detect and therefore prevent is credit card fraud, which has been exacerbated by the growth in online transactions. Large volumes of data are collected, and because of this, machines can be trained to detect financial fraud. Through pattern recognition, machines can point out irregular types of actions within different customers' profiles.
Machines are trained using algorithms as a set of instructions on how to group or cluster information in order to best draw patterns and conclusions from the overall dataset. There are many types of algorithms used to "train" machines, but the two most popular are supervised and unsupervised models.
Machines build models by digesting and labeling information to create a baseline with which to compare new information and thus detect if a new input is anomalous or not.
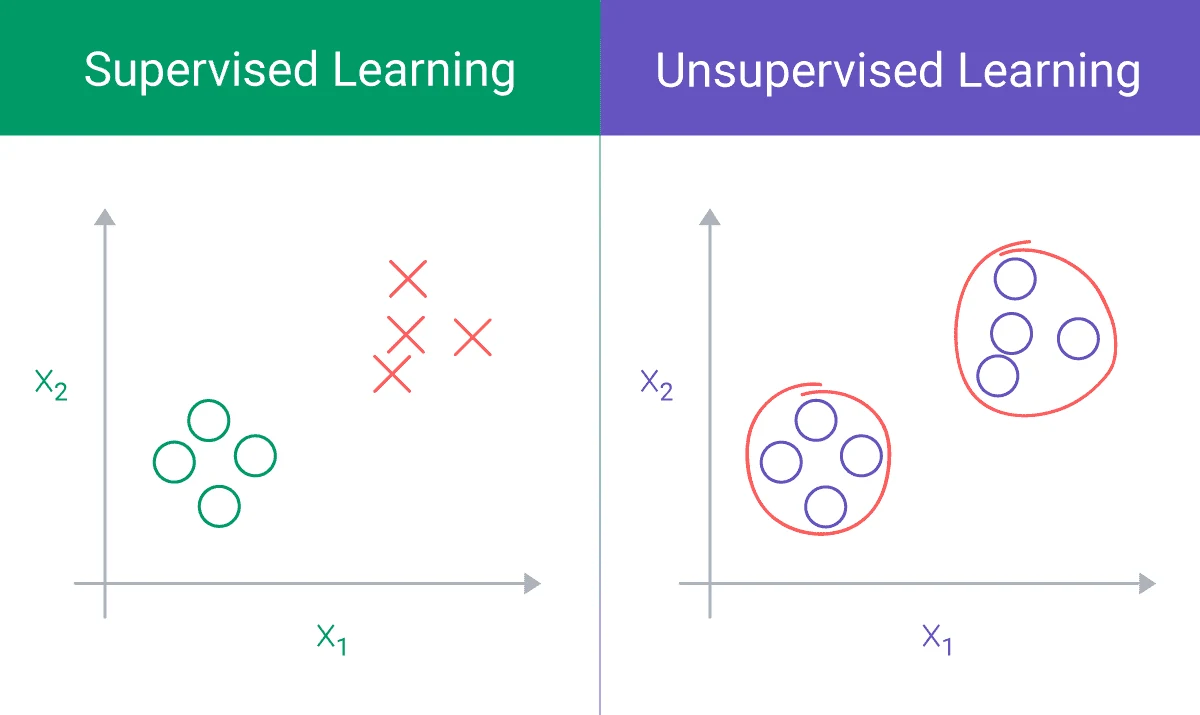
Supervised models are more common than unsupervised machine learning models, but unsupervised models can be used to detect as-yet unseen fraudulent activity.
Supervised Models
A supervised model is the most common form of ML. It involves feeding a machine a set of labeled or "tagged" inputs. For the financial industry, this data set can be transactions "tagged" to show whether it is or is not fraudulent.
Machines then digest massive amounts of tagged transaction details so they can create and understand consumer patterns that best reflect legitimate behaviors. The more information used in creating a supervised model, the more accurate the baseline model will be.
Unsupervised Models
Unsupervised models are different from supervised in that the model is constructed from data that is not tagged. This is usually because it is difficult to identify which details will lead to the output desired. Instead, a form of self-learning must be used to reveal patterns in the data that are invisible to other forms of analytics.
These types of models are used to find outliers that were previously unknown, such as new fraudulent activity that has not been seen before. Discrepancies in the data that might indicate fraudulent activity are evaluated at the individual level as well as through sophisticated group comparison.
The Benefits
ML can be applied to many areas of the payment process to proactively prevent fraud. According to the above-cited Teradata case study, the detection of real fraud was increased by 50%.
This helps not only ensure clients' accounts remain safe, their information and money intact, but also helps lower overhead costs incurred when time is spent on the phone or otherwise helping clients mitigate the fall out of a scam, successful or otherwise.
Some examples of machine learning application include:
- Better data credibility assessment: Computers can be taught to verify and validate personal details via public sources and transaction histories. This helps bridge gaps that might appear in transaction sequences. By reconciling paper documents and system data, ML can eliminate the human factor usually required in these scenarios.
- Evaluate duplicate transactions: Because of the rising speed and number of transactions, a popular scam is to either create a new transaction as close as possible to a valid transaction, or to duplicate an existing transaction to look like a computer or input error. Rule-based systems often fail to distinguish between error or unusual transactions from true fraud. ML, on the other hand, can detect patterns in consumer spending and flag activity that truly seems suspicious. And with the inevitable arrival of more data from which to learn, machines will only get smarter.
- Mine existing behavior analytics: Much of current fraud detection relies on behavior analytics, which is understanding how a client typically spends their money. This can be expressed in regular visits to ATMs, typical spending patterns shown in times and dates, and other metrics. These metrics provide rich sources of data to train machines on client patterns and what might result or point to a fraudulent transaction.
Conclusion
Machine learning offers financial institutions many benefits: it works with existing company data, can increase customer satisfaction, and lessen the amount of work needed to keep accounts and business assets safe. By securing customers' information and money, a financial organization secures their reputation and their future.
By using existing data sets, banks and other financial institutions can create unique fraud prevention systems that grow with their business and understand their customers on a level that rule-based systems cannot.
When aiming to improve your fraud prevention strategies, it's essential to collaborate with a partner who truly understands the complexities of the fintech sector. Softjourn offers financial software development services that enhance fraud detection capabilities while minimizing false positives.
Our team of experts is well-versed in AI and machine learning technologies, ensuring that you won't have to spend time explaining the intricacies of the fintech industry.
Instead, by choosing a knowledgeable partner like Softjourn, you can focus on implementing advanced and efficient fraud detection solutions tailored to your unique needs.
Our experience with artificial intelligence can help you personalize services and deliver real-time solutions, keeping up with the competition.








