
The Complete Guide to Kubernetes Cost Optimization: 15 Proven Strategies to Cut Container Costs in 2026
Kubernetes has revolutionized container orchestration, but it's also become a significant line item in cloud budgets. This comprehensive guide provides 15 battle-tested strategies to optimize your Kubernetes costs while maintaining performance and reliability.
Kubernetes has revolutionized container orchestration, but it's also become a significant line item in cloud budgets.
This comprehensive guide provides 15 battle-tested strategies to optimize your Kubernetes costs while maintaining performance and reliability.
Kubernetes has revolutionized container orchestration, but it's also become a significant line item in cloud budgets.
Nearly half of organizations (49%) report rising cloud costs after adopting Kubernetes, and 17% say their bills increased significantly.
This comprehensive guide provides 15 battle-tested strategies to optimize your Kubernetes costs while maintaining performance and reliability.
Why Kubernetes Cost Optimization Matters Now More Than Ever
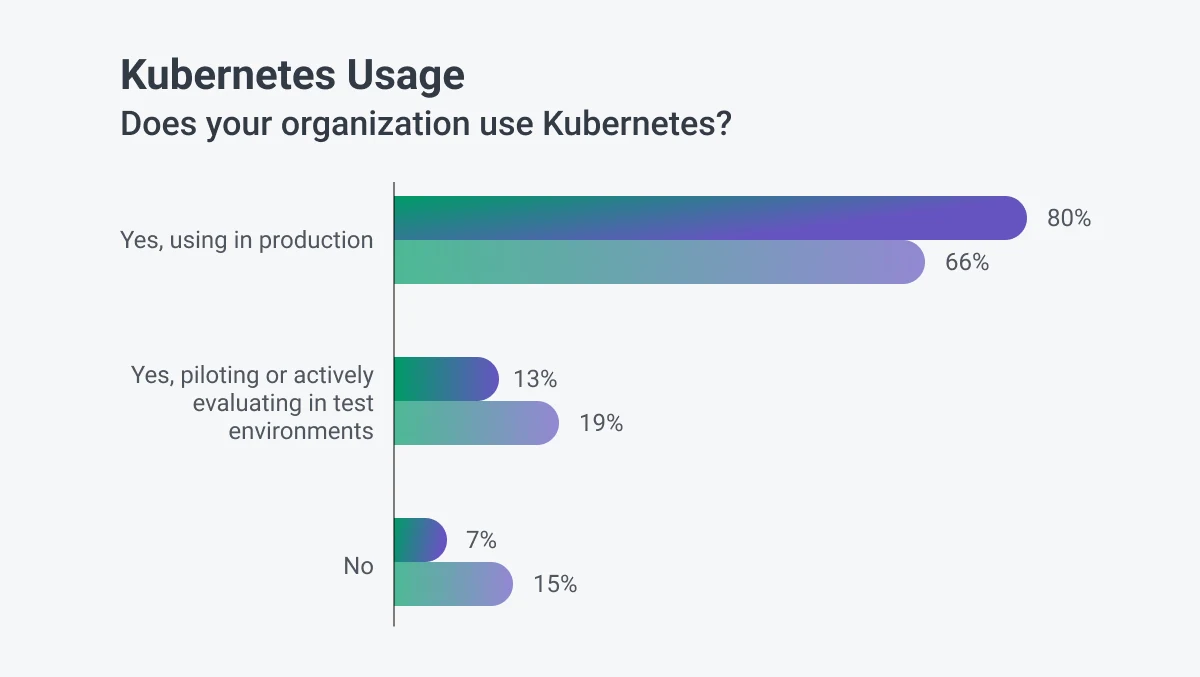
Kubernetes isn't just popular – 93% of companies are either using it in production, piloting it, or actively evaluating it, and 80% reported running Kubernetes in production in 2024, up from 66% in 2023, reflecting a strong 20.7% year-over-year growth rate.
The momentum is undeniable, with Kubernetes adoption projected to grow at a 23.4% CAGR through 2031.
But this rapid adoption brings new financial challenges. While Kubernetes offers unprecedented scalability and deployment flexibility, its abstraction layers often hide where your money is going.
Unlike traditional infrastructure with predictable pricing, Kubernetes introduces dynamic scaling, shared resources, and complex networking that can cause unexpected cost spikes.
For many organizations, Kubernetes already consumes a meaningful share of cloud budgets: 15% of companies spend more than half of their total cloud costs on Kubernetes, while others keep it below 25%.
Modern organizations running production Kubernetes workloads typically face these cost drivers:
- Compute resources: CPU, memory, and storage across nodes
- Cloud service fees: Managed Kubernetes services (EKS, GKE, AKS)
- Network traffic: Inter-zone and cross-region data transfer
- Storage costs: Persistent volumes, snapshots, and backups
- External services: Load balancers, monitoring tools, and third-party integrations

The Hidden Costs of Unoptimized Kubernetes
Before diving into optimization strategies, understanding the most common cost pitfalls is crucial for building an effective optimization plan.
Resource Overprovisioning
Teams often set resource requests with massive safety margins to avoid the dreaded OOM (Out of Memory) killer. This approach creates a false sense of security while systematically wasting resources.
Consider a where a pod requests 2GB of memory but consistently uses only 500MB during peak load. This represents 75% waste that compounds across hundreds or thousands of pods in your cluster.
The psychological factor behind overprovisioning cannot be underestimated. Development teams would rather explain a higher cloud bill than face the consequences of application crashes during critical business hours.
However, this conservative approach often leads to low resource utilization rates, meaning organizations are essentially paying for compute power they never use.
Cluster Sprawl
Development and testing clusters have a tendency to multiply and persist long after their intended purpose. The lifecycle of these environments often follows a predictable pattern:
- A developer spins up a cluster for a specific project or experiment
- The cluster serves its initial purpose successfully
- The project ends or shifts focus, but the cluster remains running
- Weeks or months pass without anyone remembering to decommission the environment
- The "temporary" cluster becomes a permanent cost center
This phenomenon becomes particularly expensive in enterprise environments where multiple teams work independently, each creating their own isolated environments without centralized oversight or automated cleanup policies.
Inefficient Autoscaling
The Horizontal Pod Autoscaler (HPA) can mask underlying inefficiencies rather than solving fundamental performance problems.
If your application has memory leaks, inefficient database queries, or poor caching strategies, the HPA will simply scale out the inefficiency, multiplying both resource consumption and costs.
This scaling approach treats symptoms rather than causes.
A properly optimized application might handle 1000 requests per second with 2 pods, while an inefficient version might require 10 pods for the same workload.
The cost difference becomes exponential when you factor in supporting infrastructure, networking overhead, and management complexity.
Storage Neglect
Persistent volumes, snapshots, and orphaned storage accumulate costs silently over time. These "zombie" resources continue consuming budget while providing no value to active workloads. Storage costs are particularly insidious because they persist even when applications are deleted, and many organizations lack proper lifecycle management policies.
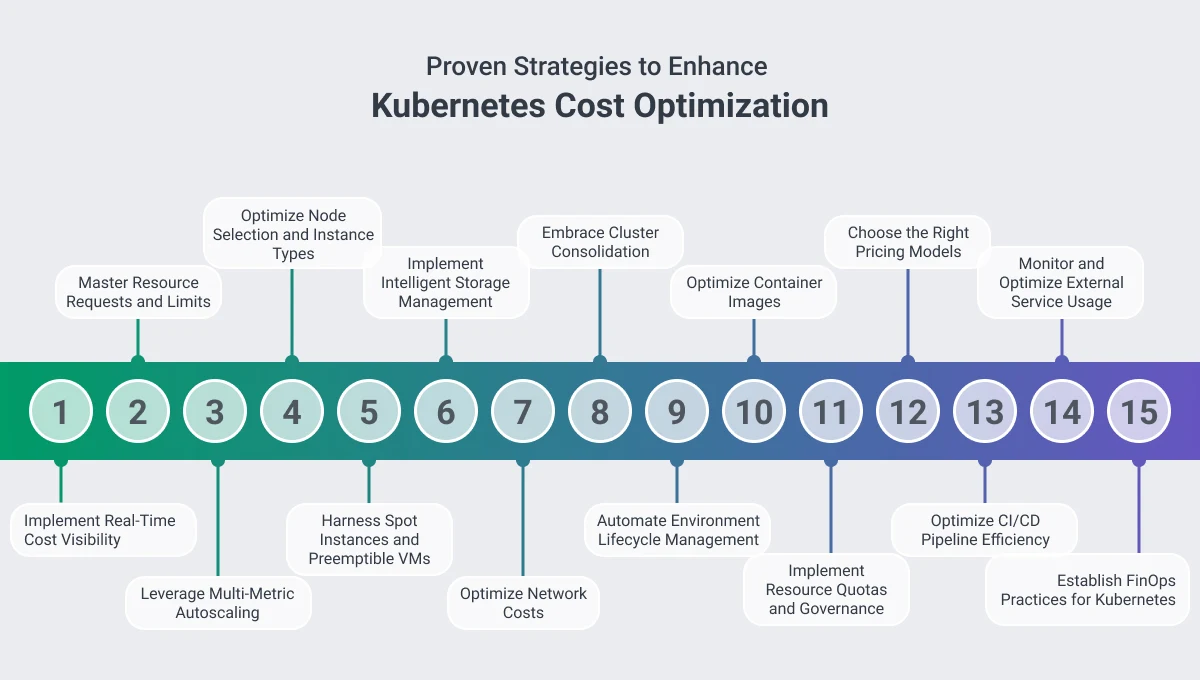
15 Proven Kubernetes Cost Optimization Strategies
1. Implement Real-Time Cost Visibility
Cost optimization begins with understanding where your money goes. Traditional cloud bills show service-level expenses but don't map to specific applications or teams within your Kubernetes environment.
The challenge with Kubernetes cost visibility extends beyond simple resource tracking. Modern containerized applications span multiple services, namespaces, and even clusters.
A single user request might touch dozens of microservices, each consuming different amounts of CPU, memory, and network bandwidth. Without proper attribution, determining the true cost of serving that request becomes nearly impossible.
Essential Implementation Steps:
- Deploy comprehensive monitoring solutions that track resource usage at pod, namespace, and cluster levels
- Implement consistent labeling strategies across all resources to enable accurate cost allocation
- Establish automated alerting systems that notify teams when spending deviates from expected patterns
- Create executive dashboards that translate technical metrics into business-relevant cost drivers
Recommended Tools:
- OpenCost: Open-source solution backed by the CNCF for basic cost tracking and allocation
- Kubecost: Enterprise-grade platform offering detailed cost analysis and optimization recommendations
- CloudZero: Business-context platform that connects infrastructure costs to customer metrics and revenue
2. Master Resource Requests and Limits
Properly configured resource requests and limits form the foundation of cost optimization. Resource requests guarantee minimum resources for your pods, while limits prevent any single container from consuming excessive resources and impacting other workloads.
The key insight here is that resource requests directly influence your infrastructure costs, as Kubernetes schedules pods based on requested resources rather than actual usage.
For instance, if your pods consistently use only 20% of their requested CPU, you're essentially paying for 5x more compute capacity than necessary.
Implementation Strategy:
Start by gathering baseline metrics from your existing workloads. Most organizations discover significant gaps between requested and utilized resources during this analysis phase. Use monitoring tools like Prometheus to collect detailed usage patterns over at least 30 days, capturing both typical operations and peak load scenarios.
- Analyze historical usage patterns using monitoring data from Prometheus or similar platforms
- Set resource requests based on 95th percentile usage to handle normal traffic spikes
- Configure limits at 150-200% of requests to allow for temporary bursts while preventing resource hogging
- Implement regular review cycles to adjust requests as application behavior changes
3. Leverage Multi-Metric Autoscaling
Moving beyond simple CPU-based autoscaling enables more intelligent scaling decisions that respond to actual application behavior rather than generic metrics.
Traditional CPU-based autoscaling often fails to capture the true performance characteristics of modern applications. A web application might be CPU-light but memory-intensive during certain operations, or it might need to scale based on queue depth rather than resource utilization. Multi-metric autoscaling addresses these limitations by considering multiple signals simultaneously.
Advanced Autoscaling Approaches:
- Vertical Pod Autoscaler (VPA): Automatically adjusts resource requests and limits based on historical usage patterns
- Custom Metrics Scaling: Scale based on application-specific metrics like queue length, response time, or business metrics
- Predictive Autoscaling: Use machine learning algorithms to anticipate load patterns and scale proactively
- Time-Based Scaling: Implement different scaling policies for different times of day or days of the week
The combination of HPA and VPA can be particularly powerful, though it requires careful configuration to avoid conflicts between horizontal and vertical scaling decisions.
4. Optimize Node Selection and Instance Types
Choosing the right compute instances for your workloads can dramatically impact costs. The one-size-fits-all approach to node selection often leads to significant overspending on inappropriate instance types.
Different workloads have vastly different resource profiles. A machine learning training job might be GPU-intensive, while a web API might be CPU-bound with minimal memory requirements. A data processing pipeline might need high memory capacity but relatively modest CPU power. Matching instance types to workload characteristics ensures you're paying for the resources you actually need.
Node Optimization Strategies:
- Workload Profiling: Analyze your applications to understand their resource consumption patterns and requirements.
- Mixed Instance Types: Deploy different node pools optimized for different workload categories within the same cluster.
- ARM-Based Instances: Consider AWS Graviton, Azure Ampere, or Google Tau instances.
- Spot Instance Integration: Use interruptible instances for fault-tolerant workloads.
5. Harness Spot Instances and Preemptible VMs
Spot instances represent one of the most significant opportunities for cost reduction in Kubernetes environments, offering major discounts compared to on-demand pricing.
The key to successful spot instance adoption lies in architectural preparation rather than simply switching instance types. Applications must be designed to handle interruptions gracefully, and infrastructure must be configured to maintain service availability even when individual nodes disappear with minimal notice.
Implementation Best Practices:
- Diversification Strategy: Spread workloads across multiple instance types and availability zones to reduce interruption impact
- Graceful Degradation: Design applications to handle node losses without service disruption
- Mixed Instance Deployments: Combine spot instances with on-demand instances to balance cost savings with reliability requirements
- Workload Suitability Assessment: Prioritize batch jobs, development environments, and stateless applications for spot instance deployment
Recommended Tools:
- AWS Spot Fleet: Automatically manages spot instance procurement and replacement
- Azure Virtual Machine Scale Sets: Handles mixed instance type deployments with automatic failover
- Google Cloud Preemptible VMs: Offers predictable pricing with 24-hour maximum runtime
6. Implement Intelligent Storage Management
Storage costs can quietly consume significant portions of your Kubernetes budget, particularly when organizations lack proper lifecycle management policies.
The complexity of Kubernetes storage management stems from the persistent nature of data combined with the ephemeral nature of containers.
Volumes can outlive the pods that created them, leading to orphaned storage that continues generating costs indefinitely.
Additionally, different storage classes offer dramatically different price points and performance characteristics, making proper selection crucial for cost optimization.
Storage Optimization Techniques:
- Dynamic Provisioning: Implement automated volume creation and sizing to eliminate manual configuration errors
- Storage Class Optimization: Match storage performance characteristics to application requirements rather than defaulting to premium options
- Lifecycle Automation: Deploy policies that automatically resize volumes based on usage patterns and delete unnecessary snapshots
- Regular Storage Audits: Implement automated scanning to identify and remove orphaned volumes, unused snapshots, and oversized allocations
7. Optimize Network Costs
Network traffic, especially cross-region communication, can generate substantial costs that often go unnoticed until organizations review detailed billing statements.
Kubernetes networking costs become particularly complex in multi-region deployments where services might communicate across geographical boundaries without developers realizing the financial implications.
Each cross-region API call, database query, or file transfer incurs data egress charges that can quickly accumulate.
Network Cost Reduction Strategies:
- Locality Awareness: Design applications to minimize cross-zone and cross-region communication through intelligent service placement
- Caching Implementation: Deploy distributed caching layers to reduce repetitive external API calls and database queries
- Regional Service Endpoints: Use cloud provider service endpoints to keep traffic within regional boundaries
- Load Balancer Optimization: Choose appropriate load balancer types and configurations to minimize data processing costs
Consider implementing a network policy that requires explicit approval for any service communication that crosses regional boundaries, forcing teams to consider the cost implications of their architectural decisions.
8. Embrace Cluster Consolidation
Running multiple small clusters creates overhead and reduces efficiency compared to fewer, larger clusters with proper multi-tenancy controls.
The economics of cluster consolidation stem from several factors. Each Kubernetes cluster requires control plane resources that represent fixed overhead regardless of workload size.
Multiple small clusters also reduce the effectiveness of bin-packing algorithms, leading to lower overall resource utilization. However, consolidation must be balanced against security, compliance, and blast radius considerations.
Cluster consolidation eliminates redundant control plane overhead while improving resource utilization through better bin-packing of diverse workloads.
This approach also reduces operational complexity by minimizing the number of environments that need monitoring, security management, and compliance oversight.
Multi-Tenancy Implementation:
- Namespace Isolation: Use Kubernetes namespaces to create logical boundaries between teams and applications
- RBAC Configuration: Implement role-based access controls to ensure appropriate permissions and access restrictions
- Resource Quotas: Set limits on CPU, memory, and storage consumption at the namespace level
- Network Policies: Control communication between different tenant workloads to maintain security boundaries
9. Automate Environment Lifecycle Management
Development and testing environments should have automatic shutdown schedules to prevent unnecessary costs during off-hours, weekends, and holidays.
The challenge with development environments lies in balancing cost savings with developer productivity. Environments that take too long to start up or frequently lose state can significantly impact development velocity, potentially costing more in developer time than the infrastructure savings justify.
Lifecycle Automation Strategies:
- Scheduled Shutdowns: Automatically power down non-production environments during nights, weekends, and holidays
- On-Demand Provisioning: Enable developers to quickly spin up environments when needed and automatically destroy them after defined periods
- State Management: Implement solutions that can preserve application state during shutdown cycles to minimize startup time
- Exception Handling: Allow teams to request extensions for environments that need to run during typically off-hours periods
Implementation Tools:
- Kubernetes CronJobs: Schedule regular cleanup operations for unused resources
- Cloud Provider Scheduling: Use native cloud scheduling features for node group management
- GitOps Integration: Tie environment lifecycle to development workflow milestones
10. Optimize Container Images
Smaller, more efficient container images reduce storage costs, improve deployment times, and indirectly reduce compute costs through faster startup and lower memory overhead.
Container image optimization often gets overlooked because the individual impact seems minimal. However, when multiplied across hundreds of deployments and frequent scaling events, the cumulative effect on both storage costs and deployment efficiency becomes significant.
Image Optimization Techniques:
- Base Image Selection: Choose minimal base images like Alpine Linux or distroless images instead of full operating system distributions
- Multi-Stage Builds: Use Docker multi-stage builds to separate build dependencies from runtime requirements
- Layer Optimization: Minimize the number of layers and optimize layer caching to reduce image size and build times
- Security Scanning: Implement automated vulnerability scanning to identify and remove unnecessary packages that increase attack surface

11. Implement Resource Quotas and Governance
Preventing cost overruns through automated guardrails is more effective than reactive cost management after expenses have already occurred.
Governance policies serve multiple purposes beyond cost control. They ensure fair resource allocation among teams, prevent individual applications from impacting cluster stability, and establish accountability for resource usage decisions. However, governance must be balanced against development velocity to avoid becoming a bottleneck.
Governance Implementation:
- Namespace Resource Quotas: Set limits on total CPU, memory, and storage consumption per namespace or team
- Admission Controllers: Use tools like OPA Gatekeeper or Kyverno to enforce policies at deployment time
- Budget Integration: Connect resource quotas to actual financial budgets and automated alerts
- Exception Workflows: Create processes for requesting additional resources with appropriate approval chains
12. Choose the Right Pricing Models
Cloud providers offer various pricing options beyond standard on-demand rates. Strategic use of these options can significantly reduce costs without requiring architectural changes.
The key to effective pricing strategy lies in understanding your usage patterns and risk tolerance.
Reserved instances and savings plans require upfront commitments but offer substantial discounts for predictable workloads. Spot instances provide maximum savings but require applications that can handle interruptions gracefully.
Pricing Strategy Framework:
- Reserved Instances: Commit to specific instance types and regions for 1-3 year terms with up to 75% savings
- Savings Plans: Flexible commitment-based discounts that apply across instance families and regions
- Spot Instances: Bid for unused capacity with up to 90% discounts but accept interruption risk
- Sustained Use Discounts: Automatic discounts for consistent usage patterns on certain cloud platforms
13. Optimize CI/CD Pipeline Efficiency
Efficient build and deployment pipelines reduce the resources needed for development workflows while improving developer productivity and reducing time-to-market.
CI/CD pipeline costs often get overlooked because they're viewed as development overhead rather than production infrastructure.
Keep in mind that organizations with active development teams can spend significant amounts on build infrastructure, especially when pipelines are inefficient or poorly optimized.
We recommend measuring and optimizing total pipeline execution time; monitoring CPU, memory, and storage; tracking the effectiveness of caching strategies across different components; and calculating the total cost of running pipelines including compute, storage, and networking.
Pipeline Optimization Strategies:
- Build Caching: Implement aggressive caching strategies for dependencies, intermediate build artifacts, and Docker layers
- Parallel Execution: Design pipelines to run independent tasks concurrently rather than sequentially
- Resource Right-Sizing: Match build runner specifications to actual pipeline requirements rather than using default configurations
- Spot Instance Integration: Use interruption-tolerant instances for build workloads to achieve significant cost savings
14. Monitor and Optimize External Service Usage
Third-party services and cloud-native offerings can add significant costs to your Kubernetes deployment, often without clear visibility into usage patterns or cost drivers.
External service costs become particularly challenging to manage because they're often hidden within application logic and may not be immediately visible in infrastructure monitoring.
API calls, database queries, external storage access, backup and disaster recovery services, and third-party integrations can generate substantial costs that scale with application usage.
External Service Management:
- Usage Auditing: Implement comprehensive logging and monitoring for all external service interactions
- Cost Attribution: Map external service costs back to specific applications, teams, or customers
- Optimization Opportunities: Identify redundant calls, implement caching layers, and negotiate volume discounts
- Alternative Evaluation: Regularly assess whether expensive external services can be replaced with more cost-effective alternatives
15. Establish FinOps Practices for Kubernetes
Creating a culture of cost awareness where development teams understand and take responsibility for the financial impact of their decisions is crucial for long-term cost optimization success.
FinOps practices bridge the gap between technical teams who make resource decisions and financial teams who manage budgets and spending.
Without this alignment, cost optimization efforts often fail because the people making spending decisions don't see the financial consequences of their choices.
FinOps Implementation Framework:
- Cost Visibility: Make spending data accessible and understandable to technical teams through dashboards and regular reporting
- Accountability: Establish clear ownership of costs at the team and project level with regular review cycles
- Education: Train developers on the cost implications of architectural and operational decisions
- Incentive Alignment: Create reward structures that recognize teams for achieving cost optimization goals without sacrificing other metrics

Kubernetes Cost Optimization by Cloud Provider
AWS Kubernetes Service Cost Management
For AWS Kubernetes, focus on right-sizing resources to avoid over-provisioning CPU and memory while maintaining performance.
Use Auto Scaling to adjust cluster size based on workload demands and Spot Instances for non-critical tasks, which can reduce costs by up to 90% compared to on-demand pricing.
Fargate can eliminate node management overhead for specific workloads, while EBS GP3 volumes paired with the CSI driver optimize storage efficiency.
Manage costs effectively with AWS Cost Explorer, Budgets, and Trusted Advisor, and leverage Reserved Instances for predictable workloads to maximize savings.
Azure Kubernetes Service Cost Management
With AKS, cost optimization starts with resource quotas and limits to control consumption and avoid excessive CPU and memory usage.
Use AKS autoscaling to dynamically scale clusters and Azure Spot VMs for non-critical workloads to reduce spending.
Implement multiple node pools and Azure Container Instances for flexible, serverless scaling during peak demand.
Optimize storage through proper disk type selection and lifecycle policies, while monitoring costs with Azure Cost Management. Take advantage of Azure Hybrid Benefits and Dev/Test pricing for additional savings on Windows containers and non-production environments.

Google Kubernetes Engine Cost Management
For GKE, start by defining resource requests and limits to prevent overconsumption and wasted spend.
Enable cluster autoscaling to automatically adjust node pools and consider Autopilot mode for simplified management and per-pod pricing, especially for teams without deep Kubernetes expertise.
Use Committed Use Discounts for predictable workloads and integrate preemptible VMs for cost-effective batch and fault-tolerant tasks. Optimize storage and performance with regional persistent disks and leverage node auto-provisioning for efficient instance selection.
Measuring Success: Key Metrics for Kubernetes Cost Optimization
Tracking the right metrics ensures that cost optimization efforts deliver measurable business value rather than simply reducing expenses at the cost of performance or reliability.
Financial Metrics
- Track spending at the application level to identify the most expensive components
- Understand the infrastructure cost of serving individual customer requests or business processes
- Monitor CPU, memory, and storage utilization rates across different resource types
- Track spending patterns over time to identify optimization impact and potential areas for improvement
Operational Metrics
- Monitor CPU, memory, and storage efficiency across nodes and pods
- Track response times, error rates, and throughput to ensure optimization doesn't degrade user experience
- Measure how quickly and efficiently applications respond to demand changes
- Monitor deployment frequency and lead time to ensure cost controls don't slow down development teams
Business Metrics
- Ensure cost optimizations don't negatively impact user experience
- Monitor whether cost controls affect development and deployment speed
- Track availability and reliability metrics during optimization implementation
- Compare infrastructure efficiency to industry benchmarks and competitors

Advanced Techniques for Enterprise Environments
Machine Learning for Cost Prediction
Advanced organizations are implementing machine learning algorithms to predict and prevent cost overruns before they occur, moving from reactive to proactive cost management.
Machine learning applications in cost optimization go beyond simple trend analysis. Modern ML systems can identify complex patterns in resource usage, predict scaling requirements based on business metrics, and automatically adjust resource allocations to optimize both cost and performance.
ML Implementation Areas:
- Demand Forecasting: Use historical data to predict resource requirements and optimize capacity planning
- Anomaly Detection: Identify unusual spending patterns that might indicate inefficiencies or security issues
- Workload Optimization: Automatically match workloads to optimal instance types and configurations
- Budget Allocation: Predict future costs and optimize budget distribution across teams and projects
Multi-Cloud Cost Optimization
While multi-cloud strategies increase complexity, they can also provide cost optimization opportunities through competitive pricing and specialized service selection.
Multi-cloud cost optimization requires sophisticated tooling and processes to manage complexity while capturing the benefits of cloud provider competition.
The key is developing capabilities to move workloads based on cost efficiency while maintaining operational simplicity.
Multi-Cloud Strategies:
- Cloud Arbitrage: Move compute-intensive workloads to providers offering the best price/performance ratios
- Service Specialization: Use each provider's strengths for specific workload types (AI/ML, analytics, storage, etc.)
- Geographic Optimization: Choose providers based on regional pricing and latency requirements
- Contract Negotiation: Leverage multi-vendor relationships to negotiate better pricing with all providers

Common Pitfalls and How to Avoid Them
Over-Optimization
Focusing too much on cutting infrastructure costs can hurt performance, reliability, and developer productivity, often costing more than it saves. Successful optimization balances cost with speed, reliability, and customer experience.
Warning Signs:
- Slower response times or higher error rates
- Complaints about delayed deployments or testing
- Increased downtime or reliability issues
- Falling customer satisfaction alongside lower costs
How to Prevent It:
- Set minimum performance and reliability thresholds
- Track developer productivity as part of cost metrics
- Optimize gradually and monitor impacts
- Review results regularly with all stakeholders
Ignoring Developer Experience
Optimizations that slow developers often backfire since developer time costs far more than infrastructure. A small loss in productivity can outweigh infrastructure savings.
Best Practices:
- Include developers in planning from the start
- Prioritize changes that improve, not hinder, workflows
- Invest in automation and tooling to reduce manual effort
- Track developer productivity alongside cost savings
Lack of Governance
Without clear policies, cost optimization efforts often fade as habits return and new team members lack cost awareness. Sustainable optimization comes from making cost-conscious decisions the default.
Governance Essentials:
- Use automated policies to prevent costly misconfigurations
- Provide cost dashboards for visibility
- Include cost management in onboarding and training
- Conduct regular audits to maintain progress

The Future of Kubernetes Cost Optimization
Emerging Technologies
Several emerging technologies promise to reshape how we approach container cost optimization over the next few years.
WebAssembly (WASM) represents a potentially transformative technology for container optimization. WASM applications typically have much smaller resource footprints than traditional containers, potentially reducing both storage and compute costs significantly. While still early in adoption, WASM could become a major cost optimization lever for appropriate workloads.
Serverless Kubernetes options like AWS Fargate, Google Cloud Run, and Azure Container Instances offer pay-per-use pricing models that can dramatically reduce costs for variable workloads. These services eliminate the need to manage underlying infrastructure while providing automatic scaling and resource optimization.
AI-Driven Optimization is increasingly automating cost decisions in real time, with systems continuously learning and adapting to workload patterns - with nearly 50% of organizations running AI/ML workloads on Kubernetes, and early adopters are already experimenting with diverse use cases.
Sustainability Integration
Environmental concerns are driving the integration of carbon footprint considerations into cost optimization strategies. Organizations are beginning to optimize for both financial cost and environmental impact, recognizing that these goals often align.
Green Computing Strategies:
- Choosing cloud regions powered by renewable energy
- Optimizing workload scheduling to use excess renewable energy capacity
- Implementing more efficient algorithms and architectures to reduce overall resource consumption
- Carbon cost accounting that includes environmental impact in financial calculations
Your Path to Kubernetes Cost Mastery
Kubernetes cost optimization isn't a one-time project — it's an ongoing journey requiring visibility, collaboration, and adaptability. The most successful initiatives share these characteristics:
- Start with Visibility – You can't optimize what you can't measure. Implement robust cost monitoring and allocation tools to track usage across clusters, teams, and applications.
- Prioritize High-Impact Areas – Focus first on workloads or services that drive the highest costs instead of trying to optimize everything at once.
- Maintain Performance & Productivity – Set clear thresholds for application performance, reliability, and developer efficiency, ensuring cost savings never come at the expense of user experience or velocity.
- Embed Cost Awareness in Culture – Make cost optimization part of your organization's DNA through training, shared KPIs, and proactive decision-making rather than relying on periodic cleanup efforts.
- Enable Cross-Functional Collaboration – Align engineering, operations, and finance teams around shared cost goals to break down silos and accelerate decision-making.
- Continuously Learn & Evolve – Stay current on new cloud services, pricing models, and Kubernetes optimization techniques. Successful organizations treat cost optimization as an ongoing capability.
- Leverage Emerging Technologies – Adapt strategies as technologies like serverless containers, WebAssembly, and AI-driven optimization mature, enabling smarter and more automated cost control.
- Align with Business Outcomes – Optimize not just for lower spend but for maximizing business value, ensuring every dollar invested supports growth, reliability, and customer experience.

Final Recommendations
Remember that effective Kubernetes cost optimization requires balancing multiple objectives simultaneously.
While this guide provides specific strategies, the most successful implementations focus on building organizational capabilities that enable continuous optimization rather than pursuing one-time cost reduction projects.
Start with the strategies that align best with your current technical capabilities and organizational readiness. As your teams develop expertise and confidence with cost optimization practices, gradually implement more advanced techniques and automation.
The container revolution has transformed how we build and deploy applications. Now it's time to master the economics of that transformation and ensure your Kubernetes investments drive maximum business value.
If you're ready to take the next step, Softjourn's cloud optimization expertise and experienced DevOps teams can help you design, implement, and manage cost-efficient Kubernetes strategies tailored to your business.
Frequently Asked Questions About Kubernetes Cost Optimization
1. What is Kubernetes cost optimization?
Kubernetes cost optimization refers to using strategies, tools, and best practices to reduce the cost of Kubernetes while maintaining high performance and reliability. It involves monitoring workloads, optimizing resource usage, and automating cost controls to ensure efficient spending across Kubernetes clusters.
2. How does Kubernetes performance optimization affect costs?
Kubernetes performance optimization focuses on improving workload efficiency, scaling, and responsiveness. When your clusters run more efficiently, you avoid over-provisioning CPU, memory, and storage, which directly reduces the cost of Kubernetes while maintaining application performance.
3. What are the best practices for Kubernetes cost management?
Effective Kubernetes cost management involves:
- Implementing precise cost allocation by namespace, team, or application
- Monitoring resource usage continuously with dedicated tools
- Right-sizing Kubernetes pods and nodes for better resource optimization
- Using automated Kubernetes cost optimization features to make real-time decisions
- Tracking spending patterns to proactively identify waste
4. What strategies are most effective for Kubernetes cost reduction?
To achieve Kubernetes cost reduction, organizations can:
- Use Kubernetes resource optimization techniques to right-size CPU and memory
- Leverage autoscaling for dynamic workload management
- Choose Spot Instances or preemptible VMs for non-critical workloads
- Consolidate underutilized clusters
- Regularly review metrics to prevent unnecessary scaling
5. How does automated Kubernetes cost optimization work?
Automated Kubernetes cost optimization uses AI- and rule-driven tools to monitor workloads and make real-time scaling and resource allocation decisions. These solutions continuously analyze usage patterns, optimize cluster sizing, and help organizations save costs without manual intervention — improving K8s optimization efficiency at scale.
6. What role do Kubernetes nodes play in cost optimization?
Kubernetes nodes provide the compute power behind your workloads, so optimizing node usage is critical for Kubernetes cost optimization. Choosing the right instance sizes, using multiple node pools, and scaling nodes up or down automatically can drastically reduce operational costs while ensuring applications remain performant.
7. How can I gain visibility into Kubernetes costs?
Achieving visibility into Kubernetes costs requires using monitoring and reporting tools such as AWS Cost Explorer, Azure Cost Management, GCP Billing Reports, or third-party solutions. These provide real-time insights into spending by cluster, namespace, or workload, making Kubernetes cost management more accurate and proactive.
8. What is Kubernetes resource optimization and why does it matter?
Kubernetes resource optimization focuses on managing CPU, memory, storage, and network usage efficiently. Over-provisioning resources drives costs up, while under-provisioning risks performance issues. By continuously analyzing resource needs and right-sizing workloads, organizations achieve better K8s cost optimization without compromising performance.
9. How can container cloud optimization improve Kubernetes efficiency?
Container cloud optimization integrates Kubernetes resource planning with broader cloud cost management strategies. It ensures workloads scale effectively across hybrid or multi-cloud environments, reduces waste, and aligns Kubernetes optimization goals with overall cloud cost optimization strategies.
10. Does AKS cost optimization differ from EKS or GKE?
Yes. AKS cost optimization focuses on Microsoft Azure's Kubernetes pricing model, which has different cost drivers compared to Amazon EKS or Google GKE. While the core principles of Kubernetes cost optimization remain the same, specific strategies like Azure Spot VMs, Reserved Instances, and integration with Azure Cost Management make AKS unique.
11. Can cloud-based Kubernetes help reduce costs?
Yes. Running Kubernetes on managed cloud services like EKS, GKE, or AKS provides built-in autoscaling, managed nodes, and efficient resource optimization. When properly configured, cloud-based Kubernetes often results in lower operational costs compared to on-premises clusters.
12. Is Kubernetes cost optimization a one-time effort?
No — Kubernetes cost optimization is an ongoing process. As workloads, cloud pricing models, and business needs evolve, organizations must continuously review usage, adopt automation, and adjust cost strategies to maintain effective Kubernetes cost management over time.
13. How much does Kubernetes actually cost to run?
The cost of Kubernetes varies based on cluster size, cloud provider pricing, workload demands, and storage usage. Factors like autoscaling efficiency, monitoring tools, and third-party integrations also influence the total cost. Proactive Kubernetes cost optimization ensures you maximize the business value of your infrastructure investment.
14. How can DevOps teams improve Kubernetes optimization?
DevOps teams play a key role in K8s optimization by monitoring usage, configuring autoscaling, and integrating cost management tools into CI/CD pipelines. With the right Kubernetes optimization practices, DevOps ensures your infrastructure runs at peak efficiency while keeping costs predictable.








